[Yongggg's] TinyBERT: Distilling BERT for Natural Language Understanding
안녕하세요 저번 장에서 다룬 'NLP Model 경량화' 기법들 중에서 많이 연구되고 있는 Knowledge Distillation 방법의 한 연구를 소개해드리려고 합니다.
연구 제목은 'TinyBERT: Distilling BERT for Natural Language Understanding'이라는 논문이며, 다른 Distillation 연구들과 비교하여 다른 방법의 layer feature Distillation을 통해 가벼우면서도 성능을 유지하는 모델을 소개한 논문입니다.
source Jiao, Xiaoqi, et al. "Tinybert: Distilling bert for natural language understanding." arXiv preprint arXiv:1909.10351 (2019).
지금부터, 논문에 대한 review를 시작하겠습니다.
1. Introduction
많은 Pre-trained Language Models(PLMs: BERT, XLNet, ELECTRA ...)은 많은 개수의 parameter를 갖고 있기 때문에 Inference time이 오래 걸릴 뿐만아니라, 메모리 문제로 인해 mobile phones과 같은 device에 탑재하기 어렵다.
해당 연구에서는 transformer 기반 모델의 새로운 Knowledge Distillation 기법을 제안하여, $BERT_{base}$의 성능에 많이 뒤쳐지지 않는 가벼운 언어 모델을 개발했다. 이 연구에서 제안한 방법의 결과는 아래와 같다.
- 4개의 layer로 이루어진 TinyBERT 모델은 GLUE 벤치마크 데이터셋에서 $BERT_{base}$의 성능을 96.8% 유지함.
- 위의 4개의 layer로 이루어진 TinyBERT 모델은 $BERT_{base}$ 모델보다 7.5배 작고 9.4배 빠름.
- 6개의 layer로 이루어진 TinyBERT 모델의 경우, teacher model과 비교하여, 성능 감소가 없음
그리고 BERT가 pre-train후 fine-tuning을 하는 2 단계의 paradigm에 맞게 효과적인 Knowledge Distillation(KD) 전략을 설계하는 것이 타당하다고 소개하였다. 따라서 [그림 1] 처럼, pre-train 단계의 지식을 전이 시키는 General Distillation 과정과, fine-tuning 단계의 지식을 전이시키는 Task-specific Distillation 단계로 이루어져있다. 이 때, Task-specific Distillation에서는 데이터 부족 문제가 있을 수 있기 때문에, Data Augmentation을 진행한 뒤, Task-specific Distillation을 진행했다.
2. Method
2.1 Layer Selection
본 논문에서는 student model의 layer 또한 teacher model로 부터 어떻게 선택하는 지가 중요하다고 밝혔으며, 본 논문에서는 다음과 같은 문제를 정의하고, 해당 문제를 실험적으로 비교하여 layer selection을 진행했다.
먼저 teacher model에 N개의 transforemr layer가, student model의 M개의 transformer layer가 있다고 하자. 이 때, 어떻게 N개의 layer에서 M개의 layer를 고르는 가의 문제로 정의하였다.
본 논문에서는 'layer mapping function : $N=g(m)$'을 통해 student layer가 어떤 함수의 input으로 들어갔을 때, teacher layer가 나오도록 하는 함수를 정의했다. 0번째 layer는 embedding layer, M+1번째 layer는 예측 layer로 매핑이 되며, 이는 $0=g(0)$, $N+1=g(M+1)$ 함수로 나타낼 수 있다.
Layer Selection strategy는 크게 세 가지로 나타낼 수 있으며 각 전략은 다음과 같다.
- Uniform strategy : $S=\lfloor {N \over M} \rfloor, \lfloor {2N \over M} \rfloor, \lfloor {3N \over M} \rfloor, \cdots, N$
- Top strategy : 가장 위의 layer부터 N개만큼 선택
- Bottom strategy : 가장 아래의 layer부터 N개만큼 선택
본 논문에서는 각 layer selection strategy를 실험적으로 비교했을 때, Uniform strategy 전략의 layer selection이 가장 성능이 우수했다고 밝혔다.
2.2 Transformer Distillation
본 논문에서는 다른 연구의 지식 전이 방법과 다른 transformer Distillation을 진행했다. transformer Distillation에서는 두 가지의 feature를 전이하도록 했다. 첫 번째로는 Attention Matrices를 전이하는 Attention-based Distillation을 진행했고 두 번째로는 transformer의 output feature를 전이하는 Hidden state-based Distillation을 진행했다. [그림 1]은 해당 transformer Distillation 과정을 나타낸다.

Attention-based Distillation의 특징은 다음과 같다.
- BERT에 의해 학습된 attention weights은 상당한 언어적 지식을 포착할 수 있다는 연구(Clark et al., 2019)에서 영감을 얻음.
- $L_{attn} = {1 \over h} \sum_{i=1}^{h}MSE(A^{S}_{i}, A^{T}_{i})$, where $h$ : number of attention head, $A_{i} \in R^{l \times l}$ : Attention matrix of i-th head
- Softmax(A) matrix를 전이하는 것 보다 unnormalized attention matrix A를 전이하는 것이 더 빠른 수렴 속도와 성능을 보임.
Hidden state-based Distillation의 특징은 다음과 같다.
- transformer의 output feature를 전달 하려는 목적임.
- $L_{hidn} = MSE(H^{S}W_{h},H^{T})$, where $H^{S} \in R^{l\times d^{'}}$, $H^{T} \in R^{l\times d}$, $d^{'}<<d$, $W_{h} \in R^{d^{'} \times d}$ : student network into same space as the teacher network's space
2.3 Embedding-layer Distillation
또한 본 연구에서는 Hidden state-based Distillation과 유사하게, Embedding layer에서도 Distillation을 진행했으며, 해당 Loss는 $L_{embd}=MSE(E^{S}W_{e},E^{T})$, where $E^{S}$ and $E^{T}$: embeddings of student and teacher networks. 와 같이 나타낼 수 있다.
2.4 Prediction-layer Distillation
또한, 중간 layer의 feature를 잘 배울 수 있도록 teacher model의 predction에 대해서도 Knowledge Distillation을 진행하였다. 구체적으로 teacher nework의 logit과 student network의 logit 사이에 penalized soft cross-entropy loss를 사용하였다. $L_{pred} = CE(z^{T}/t, z^{S}/t)$, where $z^{S}$와 $z^{T}$는 각각 student와 teacher model로 예측한 logit vector이다. $t$는 teamperature value를 의미하며 $t=1$인 경우에 가장 좋은 성능을 보였다고 한다.
위의 3가지 loss를 다음과 같이 통합할 수 있으며,
$$ L_{layer} \cases{L_{embd}, & m=0 \\ L_{hid} + L_{attn}, & M $\ge$ m > 0 \\ L_{pred}, & m=M+1}$$
최종 로스는 다음과 가팅 hyper paramete $\lambda$와 곱하여 사용했다.
$$L_{model}=\sum_{x \in X} \sum_{m=0}^{M+1} {\lambda_{m} L_{layer}(f_{m}^{S}(x), f_{g(m)}^{T}(x))}$$
이 때, pre-train Distillation 단계에서는 logit loss(prediction-layer Distillation loss)는 사용하지 않았고 그 이유는 다음과 같다.
- BERT의 중간 구조를 학습 하도록 하는 것이 목표였기 때문에, 예측층의 전달을 하지 않음.
- pre-train 단계에서 해당 Distillation을 진행했음에도 불구하고 downstream task 작업에 추가적인 개선이 되지 않음.
2.5 Task-Specific Distillation & Data Augmentation
위의 Distillation loss를 사용하여 pre-train model의 General Distillation을 마친 후, pre-train이 끝난 student model과 fine-tuning BERT model을 이용하여 두 번째 단계인 task-specific distillation을 진행한다. 이 때, task-specific에서 traing set의 부족 문제 때문에, data augmentation 방법을 제안하였으며, 그 방법은 간략하게 pre-trained language model BERT와 GloVe 단어 임베딩을 사용하여 word-level replacement를 진행하는 것이다.
자세한 data augmentation 방법은 다음과 같다.

해당 알고리즘을 풀어 설명하자면, 다음과 같다.
- 각 example 마다 몇 개의 augmentation을 수행할 지, augmentation을 진행할지 안할지에 대한 threshold, 후보군 집합의 크기를 hyper parameter로 설정함.
- 각 sequence의 단어가 single piece라면 BERT로, 아니라면 GloVe로 대체함.
- Uniform 분포의 난수보다 threshold 값이 크다면, replacement를 진행함.
3. Results
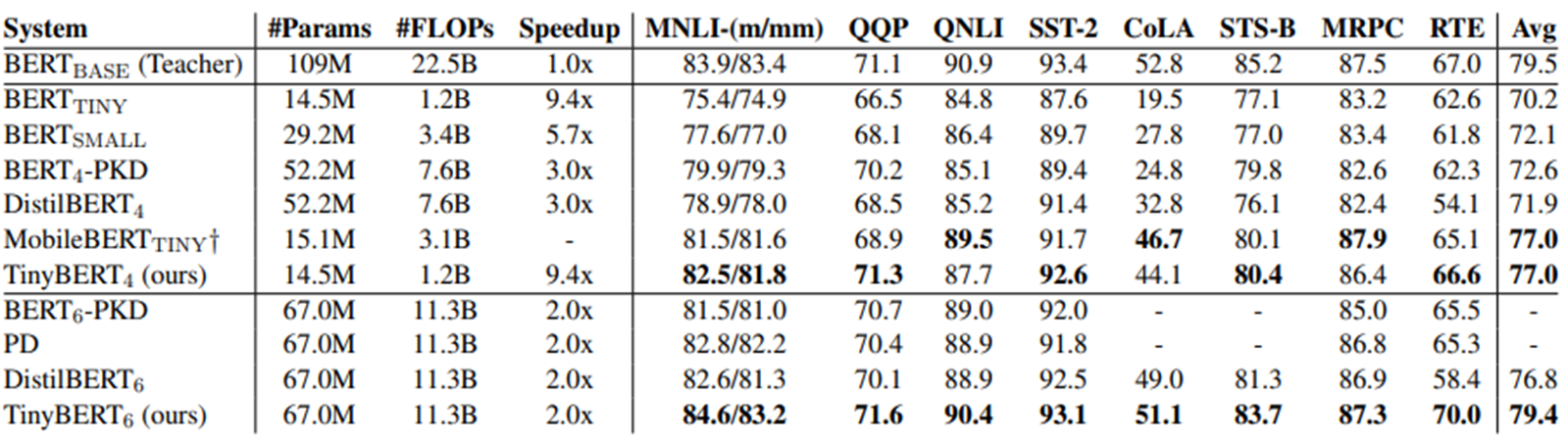
다음의 결과 표를 보면, $BERT_{base}$와 비교하여, TinyBERT의 parameter 수는 현저히 감소된걸 볼 수 있으며, 추론 Speed도 빨라진 것을 볼 수 있다. 이렇게 모델이 가벼워 졌음에도 불구하고 $BERT_{base}$와 벤치마크 데이터셋의 성능 결과를 비교했을 때, 오히려 성능이 좋아지는 것을 확인할 수 있다.
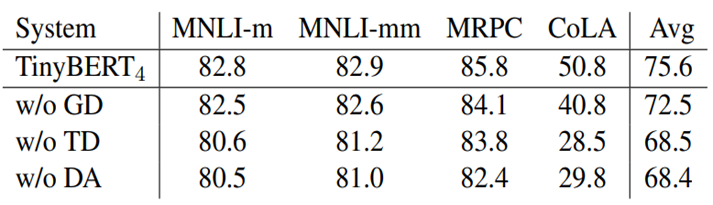
또 다음 그림에서는 해당 논문에서는 각 Distillation(GD, TD)과 Data Augmentaion(DA)을 진행 했을 때, 하지 않았을 때의 성능을 비교하였다. 모든 Distillation을 적용한 TinyBERT 모델의 성능이 가장 높았으며, 각 Distillation을 하지 않은 경우의 성능은 다음과 같다.
또, 본 논문에서는 각 Distillation 과정에서 각 distillation method를 진행 했을 때와 하지 않았을 때의 경우 또한 실험하였다. 이 실험에서도 모든 distillation method를 이용한 TinyBERT 모델이 가장 우수한 성능을 가졌으며, 각 method를 진행했을 때와 안했을 때의 결과 표는 다음과 같다.

4. A Comparision between TinyBERT and DistilBERT
다음으로는 개인적으로 생각했을때, DistilBERT와 TinyBERT의 특징을 비교하여 정리해보았다.
| DistilBERT | TinyBERT | |
| Layer Selection | Teacher model에서 2개의 layer 마다 1개의 layer를 떼어냄. | Layer Selection을 위한 Mapping function을 사용함. |
| Loss | - soft target probability loss - masked language modeling loss - cosine embedding loss |
- output of embedding layer loss - transformer-layer distillation loss - attention matrices loss - hidden state loss - logit output loss |
| KD method | 1 Stage Diustillation | 2 Stage Distillation |
| Disadvantage | 예측 성능이 높지 않음. | fine-tuned model 까지 존재해야 학습이 가능함. |
필자가 생각하는 TinyBERT의 가장 큰 단점은 모든 단계마다 Distillation 과정을 해줘야 하는 번거로움(2 Stage Distillation 때문)이 있다. 이는 pre-train 모델로 바로 task-specific 학습에 적용할 수 있는 방법보다 매우 번거롭다는 생각이 든다. 실질적으로 pre-train 모델까지 본인이 직접 학습한다고 가정했을 때, hyper parameter 튜닝을 최대 4번까지 해야하는 상황이 발생할 수 있기 때문이다. 하지만, 모든 pre-train model과 fine-tuning model을 갖고 있는 상황에서 경량화를 한다면, 좋은 경량화 방법이라고 생각한다.
이렇게 저번 글에 이어서 TinyBERT에 대한 자세한 review를 해보았습니다. 4에서는 제 개인적인 생각을 적어보았는데, 아닌 것 같다라는 생각이 드시면 댓글 남겨주세요! 같이 생각해보았으면 좋겠습니다!
다음에도 유익한 딥러닝 모델 관련 글로 찾아뵙겠습니다! 긴 글 읽어주셔서 감사합니다 ^^!