-
[yongggg's] A Survey on Audio Diffusion Models: Text To Speech Synthesis andEnhancement in Generative AI 요약(2)Machine & Deep Learning 2025. 4. 28. 15:11
이전 장의 A Survey on Audio Diffusion Models: Text To Speech Synthesis andEnhancement in Generative AI 요약(1)에서는 소리의 기초 지식과 소리에서의 Diffusion model의 배경인 DDPM 모델을 자세하게 다루었고, Acoustic model이 어떻게 발전되어 왔는지, 어떤 역할을 하는지를 살펴보았습니다.
https://yongggg.tistory.com/100
[yongggg's] A Survey on Audio Diffusion Models: Text To Speech Synthesis andEnhancement in Generative AI 요약(1)
안녕하세요 요즘 TTS 연구에 필수로 들어간다고해도 과언이 아닌 Diffusion model의 survey 논문을 소개 해드리겠습니다. Diffusion model은 vision model에서 연구가 먼저 되었지만, 음성 합성 분야에 많이 쓰
yongggg.tistory.com
이번 장에서는 Vocders 부분부터 해당 논문을 이어서 요약해보겠습니다!
3.3 Vocoder
Neural vocoders는 Mel-Spectrogram(음향 특징)을 기반으로 파형을 생성한다. 2020년까지 초기 vocoders는 autoregressive model이 고품질의 output sample을 생성했기에 인기가 컸지만, 추론 속도가 느리다는 단점이 있었다.
non-autogressive 방법은 추론 속도를 크게 향상시키지만, autogressive 방법에 비해 품질이 낮다. diffusion model을 vocoder에 적용한 최근의 연구는 다음 표와 같다.

3.3.1 Pioneering works. (선행 연구)
* WaveGrad
Score Matching과 diffusion model을 결합한 선구적인 연구이다. 데이터의 log-density의 기울기를 추정함으로써 Non-Autogressive와 Autogressive 방법간의 audio quality 차이를 줄였다. 또, Discrete Refinement Step Index와 Continuous
Noise Level을 조건으로 하는 두 가지 모델의 변형을 제안했는데, 여기서 추론시 다양한 정제 Steps을 고려했을 때, 연속적인 변형이 더 효과적이고 유연하다는 것을 발견했다. WaveGrad는 6번의 정제 steps만으로도 고품질 샘플을 생성했다.
* DiffWave
vocoders 작업에서 Mel-Spectrogram을 조건으로 하여 강력한 autogressive model과 비슷한 음성 품질을 달성했다. 또, Unconditional 설정과 class-Conditional 설정에서 현실적인 음성을 생성하고 단어 수준의 발음 일관성을 유지할 수 있었다.
DDPM의 대부분 Process를 따르며, architecture는 다음과 같다.

WaveNet과 다른 bidirectional dilated convolution (Bi-DilConv) 아키텍처를 기반으로 네트워크 $\epsilon_\theta: \mathbb{R}^{L \times N} \rightarrow \mathbb{R}^L$을 구축한다. 네트워크는 autoregressive가 아니므로 latent $x_T$에서 길이가 $L$인 오디오 $x_0$을 생성하려면 $T$ step의 forward pass가 필요하다. 여기서 $T$는 waveform 길이 $L$보다 훨씬 작다. 네트워크는 $C$개의 residual channel이 있는 $N$개의 스택으로 구성된다. 이러한 레이어는 $m$개의 블록으로 그룹화되고 각 블록은 $n=N/m$개의 레이어를 가진다. 각 레이어에서 kernel size가 3인 Bi-DilConv을 사용한다. Dilation은 각 블록 내의 각 레이어에서 두 배가 된다. WaveNet에서와 같이 모든 residual layer의 skip connection을 합산한다.
residual channel: 내부 구조에서 Conv1$\times$1 의 feature map channel 수
3.3.2 Towards efficient vocoders.
DDPM은 학습과 샘플링에 동일한 Noise 샘플링을 사용하기 때문에, 고품질 생성을 위해 수천 번의 샘플링 iteration이 필요하다. 이 많은 Iteration 작업의 속도를 개선하기 위해 많은 연구들이 등장했다. WaveGard, DiffWave도 그 연구에 포함되지만, 이 연구들은 noise 스케쥴을 특정하게 설계하여 쉽게 일반화가 가능하지 않았다.
* DDIM
학습 스케쥴에서 Subsequence를 탐색하는 방법을 제안했다. 예를 들어 학습 시 1000단계의 Noise 스케쥴을 사용하더라도, 샘플링 시에서는 일부 단계(subsequence)만 선택하여 더 적은 단계로 진행한다. 이 연구는 짧으면서 효과적인 subsequence를 찾기 어렵다는 문제와 잘못된 subsequence를 선택했을 때, 품질의 저하가 단점이었다.
Schedule prediction by additional networks.
* Bilateral Denoising Diffusion Model(BDDM)
샘플링을 위한 더 짧은 Noise 스케쥴을 찾기 위해, 추가적인 스케쥴 Networks로 직접 예측하는 방법을 제안했다. DDPM의 기존 score networks는 그대로 사용하고, BDDM을 노이즈 제거 모델로 사용하여 계산 비용을 조금 늘리는 대신 빠른 수렴을 얻을 수 있었다.
Vocoder 작업에서 BDDM은 단 7-steps만으로 인간 음성과 구분할 수 없는 샘플을 생성하며, WaveGrad 보다 143배, DiffWave보다 28.6배 빠른 속도를 달성했다.
Efficient inference by joint training.
* InferGrad
추론 반복 횟수를 줄이며 생성 품질을 유지하기 위해 추가 Loss를 도입하여 추론 과정을 학습에 통합하는 방법을 제안했다. DDPM의 reverse process에 사용되는 noise schedule $\hat{\beta}$가 forward process에서 정의되는 $\beta$와 다를 수 있다고 가정한다.
Infer Loss.
- 일반적으로 DDPM의 추론 속도를 향상시키기 위해서는 diffusion step 수 $T$와 reverse step 수 $N$을 $N << T$로 설정한다. 이렇게 설정하면, $N$이 상당히 작아지므로, noise schedule $\hat{B}$에 대한 선택이 중요하게 된다.
- 그러나 DDPM training objective는 특정 $\hat{\beta}$를 최대화하지 않는다.
- 따라서 InferGrad는 $N$이 작을 때, DDPM의 sample 품질을 향상하는 것을 목표로 한다.
- 통합된 추론 schedule에 따른 random noise로 부터 생성된 waveform과 같이 ground-truth 사이의 차이를 최소화 하는 Infer loss를 도입한다.
- Infer loss로 부터 추론 schedule을 선택하는 방법을 논의한다.
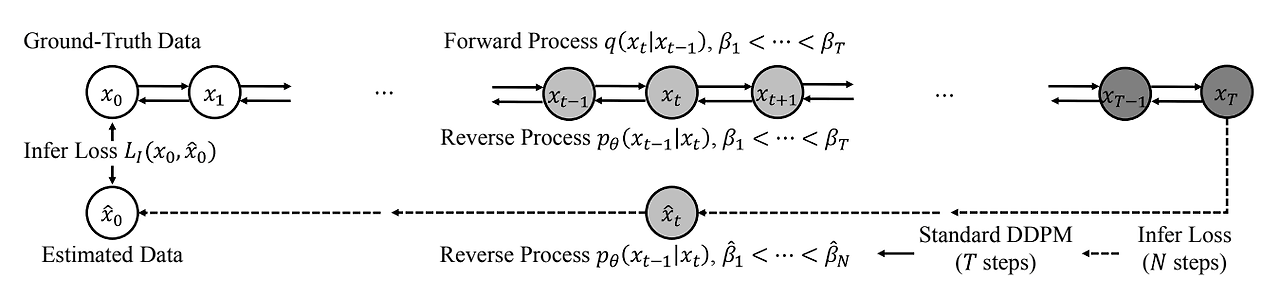
$ N = T $일 때 DDPM의 reverse process는 diffusion process의 반대로서, $ x_{T} $에서 데이터 샘플 $ \hat{x}_{0} $를 생성한다. 이때, 빠른 샘플링을 위해 $ N << T $로 설정하면, 두 인접한 추론 스텝 사이의 거리가 넓어지므로 생성 품질이 저하된다. InferGrad는 이를 해결하기 위해, infer loss $ L_{I} $를 사용하여 ground-truth $ x_{0} $와 생성된 샘플 $ \hat{x}_{0} $ 사이의 거리를 측정한다. DDPM의 training objective에 $ L_{I} $를 통합하면 loss는 다음과 같다.
- $ L = L_{D}(\theta) + \lambda L_{I}(x_{0}, \hat{x}_{0}) $
$ L_D $는 DDPM에서 $ L_{D}(\theta) = \mathcal{E}_{x_{0}, \epsilon, t} || \epsilon - \epsilon_{\theta}( \sqrt{\bar{\alpha_{t}}}x_{0} + \sqrt{1-\bar{\alpha_{t}}} \epsilon, t ||^{2}_{2})$로 정의되어 있으며, $ \lambda $는 infer loss weight이다. - $ L_{I} $ 설계 시 고려사항
- 각 타임 스텝 $ t $에서 ground-truth $ x_{t} $를 정확하게 정의하는 것은 어렵기 때문에, 중간 latent representation $ x_{t} $ 대신 ground-truth 데이터 $ x_{0} $를 사용하여 거리를 계산한다.
- 데이터 $ \hat{x}_{0} $는 추론 스케쥴 $ \hat{\beta} $를 통해 가우시안 노이즈 $ x_{T} $에서 생성된다.
- Infer loss를 통해 전체 reverse process가 model optimization에 통합될 수 있다.
결과적으로 $ L_{I} $를 최소화하는 것은, DDPM의 sample 품질을 향상 하는 것과 동일해진다.
$ L_{I} $에 사용된 샘플 메트릭은 인간의 perception(인지)과 관련이 높습니다. 여기서는 multi-resolution STFT를 $ L_{I} $로 활용한다.
- $ L_I = \frac{1}{M} \sum_{m=1}^{M} L_s^{(m)} $
$ L_s $는 single STFT loss, $ M $은 resolution 수
이때, magnitude와 phase 정보를 모두 사용하여 $ L_s^{(m)} $의 품질을 향상할 수 있다. - 결과적으로 $ x_{0} $와 $ \hat{x}_{0} $에 대한 $ L_{s} $는 다음과 같다.
$ L_s = \mathbb{E}_{x_0, \hat{x}_0} \left[ L_{\text{mag}}(x_0, \hat{x}_0) + L_{\text{pha}}(x_0, \hat{x}_0) \right] $
$ L_{\text{mag}} $: 멜-스케일 로그 STFT magnitude 스펙트럼의 $ L_1 $ Loss
$ L_{\text{pha}} $: STFT phase 스펙트럼의 $ L_2 $ Loss
Inference Schedules.
추론 스텝 수 $ N $이 작을 때, DDPM 샘플 품질은 추론 스케줄 $ \hat{\beta} $에 민감하다. InferGrad는 $ L_{I} $에 $ \hat{\beta} $의 범위를 포함시켜 추론 스케줄에 대한 강건성을 향상시킨니다. 적절한 범위를 결정하는 것은 학습 안정성을 유지하고 추론을 개선하는 데 도움을 준다.
보코더 작업에서 $ N << T $가 주어지면, 추론 스케줄 $ \hat{\beta} $를 결정하는 것이 필요하다.
- Diffusion process가 학습 스케줄 $ 0 < \beta_1 < \dots < \beta_t < 1 $을 통해 데이터를 가우시안 노이즈 $ \mathcal{N}(0, I) $로 변환한다고 가정하면, $ \bar{\alpha}_t = \prod_{s=1}^{t} (1 - \beta_s) $ 는 $ t=0 $일 때, 1에서 $ t=T $일 때, 0 사이의 범위를 가지는 노이즈 레벨이다.
학습 과정에서 사용되는 $ \beta $, $ \bar{\alpha} $를 기반으로, 추론에 사용되는 스케줄 $ \hat{\beta} $와 $ \hat{\bar{\alpha}} $를 아래와 같이 결정한다.
결과적으로 학습 과정에서 특정한 $ \hat{\beta} $ 대신 $ \hat{\beta} $의 범위를 고려함으로써, 추론 과정에서 $ \hat{\beta} $ 선택에 대한 강건성을 확보한다. 추가적으로 최적의 $ \hat{\beta} $를 찾기 위해 그리드 서치(Grid Search)를 사용할 수도 있다.
3.3.3 Improvement from statistical perspective(관점).
DDPM에서는 diffusion 과정 시, Gaussian noise를 사용하여, 이전 단계를 계산하지 않고 임의의 상태를 샘플링할 수 있었다.
* DDGM(Denoising Diffusion Gamma Models)
감마 분포도 adding 조건을 만족하여, Gaussion noise보다 추정된 noise에 더 잘 맞추어 DDPM의 성능을 향상시킬 수 있다고 주장했다.
WaveGrad의 noise schedule을 따르는 DDGM은 DDPM으로 생성한 것보다 오디오 품질을 더 개선했다.
* PriorGrad
Gaussian noise의 사전 분포가 샘플의 모든 mode(음성의 유성음과 무성음의 segment 차이)를 표현하는 데 부족할 수 있고, 이 문제는 실제 데이터 분포와 선택된 사전 분포 간의 불일치를 초래하기 때문에 학습 효율성을 떨어뜨린다고 주장했다.
따라서 이 연구에서는 음성 분석을 위한 Conditional diffusion model의 효율성을 개선하기 위해, 데이터 통계에서 Adaptive Prior(적응형 사전)분포를 적용 하는 방법을 제안했다.
- 조건부 데이터를 기반으로 평균과 분산을 계산한 후, 계산된 통계치를 Gaussian Prior 분포의 평균과 분산으로 매핑한다.
$\rightarrow$ 동일한 평균과 분산을 사용함으로써 Noise가 인스턴스 수준에서 데이터 분포와 유사해진다.
이로써 추론 속도를 크게 가속화하며, 고품질 output을 생성 하였고 이 방법은 Vocoders의 waveform(파형)이나 음향 모델의 Mel-Spectrogram 모두에 적용된다고 한다.
Other improvements.
* ItôWave
선형 이토 확률 미분 방정식을 기반으로한 Vocoders를 제안했다. 95%의 신뢰도로 WaveGrad, DiffWave보다 더 높은 Mean Opinion Score를 달성했다.
* SpecGrad
diffusion noise의 Spectral Envelope를 조건부 log-Mel-Spectrum에 맞추는 방식을 제안하여 고품질 대역에서 음질을 개선했다.
3.4 End-to-end frameworks
acoustic modeling과 vocoder modeling을 독립적인 과정으로 처리하는 대신, 일부 연구는 Fully End-to-End 방식으로 발전했다.
Partial End-to-End 방식과 Fully End-to-End 방식은 acoustic model과 Vocoder 모델 두 개의 모델을 사용한다는 공통점이 있지만, Fully End-to-End 모델은 이 두 모델을 공동으로 학습(Joint Training)한다는 점이 다르다. Fully End-to-End model의 특징은 acoustic features를 explicit(명백한) representation으로 사용하지 않고, single model을 통해 text에서 Waveform을 직접 생성한다는 것이다.
* GAN 기반의 Fully End-to-End model (FastSpeech 2, EATS, EFTS-Wav 등.)
대부분의 End-to-End framework는 text-speech align을 위해 mel-spectrogram을 생성하는데 의존하지만, Spectogram을 사용하지 않는 Flow-Based 방법은 Wave-Tacotron에 탐구되었고 그 방법은 단순히 Likelihood를 최대화 하는 방식으로 진행하는 것이었다.
Wave-Tacotron의 한계는 decoder가 여전히 autoregressive 하다는 점이었다.
Pioneering works. (선행 연구)
* WaveGrad2
Phoneme(음소) 단위 Sequence를 입력으로 받아 audio를 직접 생성하는 End-to-End 방식이다. WaveGrad의 Decoder를 Tacotron2의 Encoder 끝에 통합하여 Fully differentiable model을 구성했다. Duration Alignment에 있어서,WaveGrad2는 non-attention 기반 Tacotron을 사용하여 지속 시간에 대한 정보를 생성한다. 학습 중 duration predictor를 Ground-Truth duration과 가까워지도록 최적화한다. Refinement Steps를 조정함으로써 Fidelity(충실도)와 Speed간의 균형을 이뤘다.
* CRASH(Controllable Raw Audio Synthesis with High-Resolution)
드럼 sound 합성을 위한 End-to-End 모델을 제안했다. SDE(Stochastic Differential Equation)을 기반으로, CRASH는 Noise Conditioned U-Net을 사용하여 Score function을 추정했다. 또, Class-Mixing Sampling을 도입해 Hybrid sound를 생성했다.
결과적으로 CRASH는 Interpolation(보간)과 Inpainting(인페인팅)과 같은 다양한 작업에서 드럼 사운드를 생성할 수 있음을 보여주었다.
Fullband audios 생성.
이전 연구들은 대역 제한(Band-Limted)으로 인해, 제한된 주파수 대역(예를 들면, 16khz) 이하의 audio를 생성했다.
* DAG
SDE를 기반으로한 End-to-End 방식으로 Full-Band 오디오를 직접 생성하는 방법을 채택했다. 입력을 순차적으로 다운 샘플링하고, 업샘플링하는 Encoder-Decoder 구조를 도입했고 결과적으로 Label-Conditoned 방법에 비해 품질과 다양성이 개선되었다.
Itô SDE 기반의 Model.
* Itôn
ItôWave에서 영감을 받아 Itôn SDE를 기반으로 음성 합성을 위한 End-to-End model을 제안했다. Encoder-Decoder 구조 이외에도 Itôn은 Mel-Spectrogram과 waveform을 각각 생성하기 위해 Dual-Denoiser Structure를 도입했다. 또한 Itôn은 Two-Stage Training Strategy를 채택하여 첫 번째 단계에서 Encoder와 Mel Denoiser를 학습시키고 두 번째 단계에서 Wave Denoiser를 학습시켰다.
4. Speech Enhancement
diffusion model은 text-to-speech generation 이외에도 저하된 audio 품질을 개선하는 데 널리 사용됐다. 품질 저하를 유발하는 많은 요인이 있지만, 복원 유형에 따라 두 가지로 분류한다.
- 깨끗한 원본 audio에서 noise와 Reverb와 같은 perturbations(교란)을 제거한다.
- 누락된 부분을 복원하거나 원하는 부분을 추가한다.
예를 들면, Audio Super-Resolution task가 있다.
- Reverb: 소리가 공간(예: 방, 홀)에서 반사되어 지속적으로 잔향으로 들리는 효과. 소리에 공간감과 깊이를 더하는 역할을 함.
- Echo: 에코는 원음이 명확히 구분되는 개별 반사음이 일정 간격으로 반복되는 효과. 산에서 소리를 지를 때 "메아리"처럼 들림.
많은 Deep-Speech 향상 방법이 연구되었으며, 이는 두 가지 클래스로 분류될 수 있다.
- Discriminative Method: 향상된 음성과 깨끗한 음성 간의 차이를 최소화 하는 방법.
- Generative Models: 생성 모델은 깨끗한 신호의 분포를 추정함으로써 최적화 하는 방법.
Discriminative Method는 Generative Models을 사용하는 것에 비해 부자연스러운 단점이 있다. Generative class 에 속하는 diffusion model은 Discriminative class와의 간극을 메우는 좋은 방법 중 하나이다.
4.1 제거를 통한 향상
4.1.1 time-frequency domain에서의 audio 복원
A pure generative work.* CDiffuSE
diffusion model 기반으로 설계되었으며, 깨끗한 Speech와 noise가 섞인 Speech 간의 차이를 추정하도록 학습되었다. 이 특성 때문에 Discriminative Task로 간주될 수 있다고 지적되기도 했다.
* SGMSE
CDiffuSE의 방식을 pure generative model로 만들고 사전 분포를 사용하지 않기 위해, SDE(Stochastic Differential Equations)를 기반으로 한 방법을 제안했다. Score Function은 향상된 신호의 품질을 평가하고 모델 최적화를 guide하는데 사용된다.
DiffuSE와 CDiffuSE가 Time-Domain Waveform에서 diffusion을 시행하는 것과 달리 SGMSE에서는STFT(Short-Time Fourier Transform) 도메인에서 음성 향상을 탐구했다. Complex Coeeficients(복소 계수)의 Amplitude(진폭)뿐만 아니라, Phase(위상)을 직접 향상시켜 추가적인 위상 복원 없이, 역 STFT를 적용할 수 있도록 했다. 결과적으로 SI-SAR(Signal-to-Interference-plus-Signal-to-Artifact Ratio)이 3dB 향상되었다.
SGMSE의 추가 개선.
* SGMSE+
Score Matching Objective에 대한 이론적 검토를 제시하고, 추론(Inference) 중 다양한 샘플링 Configurations를 탐구했다. 이미지 생성에서 영감을 받아, Noise Conditional Score Network(NCSN) 구조를 음성 분야에 맞게 조정했으며, 음성 향상과 디리버브와 같은 여러 작업에서 SGMSE 보다 더 나은 성능을 가져왔다. Discriminative Methods와 비교했을 때, SGMSE+는 Discriminative Methods와 비고했을 때, 학습에 사용된 코퍼스와 다른 코퍼스에서 더 높은 일반화 능력을 보였다. 그리고 Single Channel Dereverberation Task에서 SoTA를 달성했다.
4.1.2 time-domain에서의 audio 복원.
* DiffuSE
DiffuSE는 확산 모델을 Speech Enhancement(Audio Denoising)에 적용한 선구적 연구이다. DiffWave에서 영감을 받았으며, 깨끗한 파형 오디오를 생성한다는 점에서 목표가 동일하지만, DiffWave는 깨끗한 Mel-Spectrogram을 조건으로 사용하는 반면, DiffuSE는 noise가 섞인 오디오를 조건으로 사용한다.
DiffuSE와 DiffWave의 주요 차이점은 Supportive Reverse process에 있다. 이 과정은 clean Spectral Features에 접근할 수 없는 상황에서 DiffuSE는 노이즈가 섞인 스펙트럼 조건을 사용하면서, 모델을 깨끗한 스펙트럼 Features로 Pre-training한다. Supportive Reverse process은 초기 지점으로 Isotropic(등방성) Gaussian Noise 대신 Noise가 섞인 Mel-Spectrogram 샘플을 사용하여 더 효율적으로 깨끗한 음성을 복원한다.
DiffuSE는 DiffWave에서 개발된 Fast Sampling Algorithm을 채택하여 Supportive Reverse process를 가속화했다. 이 논문에서는 diffusion 과정과 이 reverse 과정에서 Isotropic Gaussian Noise가 적용되었다고 가정하지만, 실생활의 Noise는 그 가정을 따르지 않기 때문에 항상 성립하지는 않는다. 따라서, diffusion과 reverse 과정 간의 Noise-type 불일치를 초래한다.
* CDiffuSE
위의 diffusion과 reverse 과정 간의 Noise-type 불일치를 초래하는 문제를 해결하기 위해 관찰된 Noise data를 통합하는 Generalized Conditional Diffusion Model을 공식화하여 Gaussian noise와 non-Gaussian Noise를 모두 추정할 수 있도록 했다. 이 결과로 우수한 성능을 가졌고, Discriminative Approache가 실패한 상황에서도 뛰어난 일반화 능력을 보여주었다.
4.1.3 Unsupervised dereverberation.
Unsupervised image restoration with diffusion models.
깨끗한 이미지와 손상된 이미지 Pair를 필요로 하지 않는 비지도 이미지 복원은 만족스러운 결과를 달성했으나, 대부분 방법은 반복 계산의 높은 계산 비용 문제로 어려움을 겪었다.
* Denoising Diffusion Restoration Model(DDRM)
데이터 문제를 해결하기 위해 일반 Contents 이미지에 대해 고품질의 다양하고 유효한 해결 방법을 효율적으로 생성할 수 있도록 하는 최초의 General Sampling-Based Restoration Method이다. 구체적으로 DDRM은 Linear Degradation Operator를 사용하여 Posterior Distribution을 샘플링한다.
Unsupervised dereverberation.
Nature Reverb의 디리버브(잔향 제거)는 이전 연구에서 많이 연구되었지만, Artificial Reverb를 제거하는 것은 여전히 도전적이다. 다양한 변형이 많아 지도 학습 방법(Supervised Methods)이 학습 데이터셋에서 보지 못한 데이터 쌍에 일반화되지 못하기 때문이다.
* DDRM(위의 모델)
대량의 쌍으로 이루어진 샘플(Paired Samples)을 필요로 하지 않고 다양한 유형의 Reverb를 처리하기 위해, Unsupervised Vocal Dereverberation(UVD) 방법을 제안했다.
* Unsupervised Vocal Dereverberation(UVD)
DDRM은 알려진 Linear Degradation Operator를 가정하지만, UVD는 Reverberation Operator가 항상 알려지지 않은 Music Dereverberation 방법으로 DDRM을 확장했다. 구체적으로, 연산자는 초기 추정 후 Weighted Prediction Error를 통해 적응적으로 보정된다. Diffusion Model에서 깨끗한(Dry 라고 많이 표현됨) 신호는 연산자 보정에 사용되며, 추정된 깨끗한 신호는 반복(Iterations)을 거쳐 생성된다. 실험 결과 객관적(Objective) 및 주관적(Subjective) 평가에서 비지도 및 지도 학습 Baseline을 모두 능가했다.
- Linear Degradation Operator: 이미지, 오디오 등이 손상되는 과정을 수학적으로 모델링한 연산자이다. 이 process가 선형성을 띄며, 깨끗한 데이터 $x$가 주어졌을 때, 손상된 선형변환 데이터 $y$를 $y = Hx + n$으로 표현할 수 있다.($H$: 선형 Degradation(열화) 연산자, $x$: 깨끗한 원본 데이터, $n$: 추가적인 노이즈, $y$: 손상 데이터)
- Reverberation Operator: 오디오 신호에 잔향이 추가되는 과정을 수학적으로 모델링한 연산자이다. 대표적으로 다음과 같이 수학적으로 표현할 수 있다. $y(t) = (h * x)(t) + n(t)$, ($h(t)$: 잔향 연산자, $*$ convolution 연산, $x(t)$: 깨끗한 오디오 신호, $n(t)$: 추가적인 노이즈(잔향 외 노이즈), $y(t)$: 잔향이 포함된 오디오 신호)
Speech Enhancement에서 two-stage refinement(정제).
음성 향상에 대한 연구는 Signal-to-Noise Ratio(SNR; 잡음비) 측면에서 상당한 개선을 해왔지만, 때때로 음성 품질(Naturalness; 자연스러움)이 저하되어 Downstream Applications의 성능 저하를 초래했다.
* Refiner
음성 향상 output의 Distortions(왜곡)을 제거하기 위해, 깨끗한 음성 데이터로 Pre-train된 Diffusion Model을 사용하여 손상된 부분(Degraded Part)을 탐지한 후, 이를 Denoising Diffusion Restoration Models(DDRM)을 이용하여 새롭게 생성된 깨끗한 부분으로 대체하는 작업을 실시한다.
이 연구는 다양한 음성 향상 방법에 대해 음성 품질을 개선하는 결과를 가져왔으며, 추후 연구에서는 모델에 통합되어 공동 최적화(Joint Optimization)을 수행할 수 있었다.

4.2 Enhancement by adding
4.2.1 Pioneering works on audio super-resolution.
Audio Super-Resolution, 흔히 Upsampling or Bandwith Extension(대역폭 확장)으로도 알려져 있으며, 낮은 sampling rate의 audio에서 대역폭을 확장하여 높은 sampling rate의 audio를 생성하는 것을 목표로 한다.
* NU-Wave
이전 연구들이 target 주파수로 16kHz를 사용했던것에 비해 16kHz, 24kHz 입력에서 48kHz Waveform(파형)을 합성한 최초의 모델이며, Audio Super-Resolution에 대해 Diffusion Model을 적용한 최초의 연구이다.
기존 Diffusion-based Vocoders 구조(ex: DiffWave, WaveGrad)를 따르는 NU-Wave는 모델을 Audio Super-Resolution task에 맞게 조정했다. 구체적으로, Noise Level Embedding으로 128차원의 사인파 벡터를 도입했다.
또한 많은 실험을 통해, Conditional Signal의 Receptive Field(수용 영역)이 Noise 입력의 수용 영역보다 커야 한다는 것을 발견하고, 서로 다른 수용 영역과 Upscaling Ratios를 가진 신호들의 Information Ensemble을 위해 Local Conditioner를 수정했다.
실험 결과, NU-Wave는 모델 용량이 더 작음에도 불구하고 모든 경우에서 baseline을 능가했다.
* NU-Wave2
NU-Wave를 두 가지 측면에서 추가로 개선했다.
- Vowels(모음)의 Harmonics(고조파)와 다양한 주파수의 대역을 생성하지 못했던 UN-Wave의 한계를 극복하기 위해, Short-Time Fourier Convolution을 채택했다.
- 초기 및 target sampling rate가 고정되어 있던 이전 모델들과 달리, 단일 모델로 모든 sampling rate의 입력을 처리할 수 있는 새로운 task인 General Neural Audio Upsampling을 정의했다.
$\rightarrow$ 구체적으로 다양한 sampling rate에 적응하기 위해, Bandwidth Spectral Feature Transform Layer를 제안했다.
Improved sampling method.
diffusion 기반 audio super-resolution은 일반적으로 Denoising Network를 저해상도 audio에 Conditioning하여 수행된다. "Conditioning and Sampling in Variational Diffusion Models for Speech Super-resolution." 연구에서는 Downsampling Schedule이 알려진 경우, 저해상도 audio를 sampling 과정에서 condition하게 주입함으로써 audio 품질을 추가로 개선했다.
이 Sampling 방법은 다른 diffusion-based super resolution 방법에도 직접 적용할 수 있다. 또한, 위 연구는 Uniform Diffusion Model(UDM)을 통해 다양한 업스케일링 비율과 같은 여러 설정에 일반화를 할 수 있다. 결과적으로 48kHz VCTK 다중 화자 벤치마크에서 SoTA Log-Spectral-Distance를 달성했다.
Improved model architecture.
"A Survey on Graph Diffusion Models: Generative AI in Science for Molecule, Protein and Material." 연구는 결정론적 수학적 열화(Deterministic Mathematical Degradation), 예를 들면 Compression(압축), Clipping(클리핑), Downsampling(다운 샘플링)으로 발생하는 음성 품질 저하를 개선했다. 손상된 Mel-Spectrogram을 조건으로, 위 연구는 Diffwave가 손상된 음성을 어느 정도 복원할 수 있음을 발견했다. 추가적인 개선을 위해, DiffWave의 원래 Upsampler를 CNN Sampler로 대체하고, 원래 Upsampler를 기준으로 하여 CNN Sampler를 별도로 학습시켰다. 다음 표5에 음성 향상 모델의 실험결과를 요약한다.

4.3 Miscallenous audio task(기타 audio 작업).
Source separation.
Source separation은 Mixed Signal에서 관심 있는 음성(Speech of Interest)을 복원하는 작업이다. 초기의 분리 연구는 STFT를 기반으로 했으며, 이는 Mixed Spectrum에서 Clean Spectrum을 얻는 것을 목표로 한다. 그러나 audio separation에서 STFT를 사용하는 것은 Phase(이상)에 민감하지 않고 높은 주파수 해상도(High-Frequency Resolution)를 필요로 하므로, Reconstruction(재구성) 정확도가 낮고 시간이 많이 걸리는 단점이 있다. 이러한 문제를 극복하기 위해, Time-Domain 접근법이 제안되었으며, 여기에는 독립 성분 분석(ICA; Independent Component Analysis)과 비음수 행렬 분해(NMF; Non-Negative Matrix Factorization)가 포함된다.
* DiffStep
Single-Channel 음성 분리에 처음 적용된 Diffusion-Based Method이다. 구체적으로 Separated Signal을 혼합 신호로 변환하는 SDE(Stochastic Differential Equation) 모델을 학습하며, 이에 따라 Reverse Process를 통해 혼합 신호로부터 개별 소스(Individual Source)를 분리할 수 있다. 또한, DiffStep은 Noise를 추가적인 Source 유형으로 간주할 수 있으므로 Audio Denoising에도 적용할 수 있다.
Voice Conversion.
Source Speaker의 음성을 Target Speaker에 맞게 편집하여 음성 신호 특징(Speech Signal Features)를 변경하는 작업이다. 전통적 연구는 Vector Quantization, Hidden Markov Models, Gaussian Mixture Models이 있다. 그러나 이러한 방법들은 전체 Spectrum이 아닌 Specific Parts of Spectrum에만 초점을 맞추기 때문에 Speech Quality가 낮은 결과를 초래했다.
* DiffSVC
위의 문제를 해결하고자 DiffSVC는 Diffusion Models을 활용했다. 구체적으로 노래 음성 변환(SVC; Singing Voice Conversion)을 위해 개발되었으며, 먼저 음소 후방그램(PPGs; Phonetic Posteriorgrams)을 Spectral Features로 변환한 후, 학습된 Neural Vocoder를 통해 이를 Waveform으로 변환한다. 이 방법은 임의의 다른 음성을 입력으로 사용하여 target 음성을 생성할 수 있다.
Towards a Unified framework for multiple task.
* CQT-Diff
Pretrained Model이 추론(Inference) 중 열화 유형(Degradation Type)을 알지 못하더라도 다양한 작업에 사용될 수 있는지를 탐구한다. 구체적으로 CQT-Diff는 대역폭 확장(Bandwidth Extension) 작업에서 뛰어난 성능을 보이며, Long Audio Inpainting 및 Declipping 작업에서 재학습 없이 Baseline Method에 비해 경쟁력 있는 결과를 달성했다.
이 방법이 CQT-Diff로 명명된 이유는 강한 고조파 신호를 처리하기 위해, 상수-Q 변환(CQT, Constant-Q Transform)을 채택했기 때문이다.
* "Universal Speech Enhancement with Score-based Diffusion."
일반적인 배경 소음과 잔향(Reverberation) 외에도, 대역폭 감소(Bandwidth Reduction), Clipping, 무음 구간(Silent Gaps) 등 수많은 왜곡이 존재할 수 있다고 지적했다. 따라서 55가지 서로 다른 왜곡을 End-to-End 방식으로 처리할 수 있는 범용 시스템(Universal System)을 제안했다. 작업의 주요 부분을 처리하는 Conditioner Network와 함께, Waveform Synthesis를 위해 Score-Based Diffusion Models를 기반으로 Generator Network를 구성했다. 결과적으로 전문 Listener를 대상으로 한 주관적 테스트에서 SoTA를 달성했다.
'Machine & Deep Learning' 카테고리의 다른 글