-
[Yongggg's] Survey for Compression of NLP ModelMachine & Deep Learning 2022. 4. 4. 12:46
안녕하세요 오늘은 NLP 모델의 경량화 부분으로 "Compression of NLP Model"의 Survey 논문을 읽고 여러가지의 모델 경량화 방법을 압축하여 설명드리겠습니다.
모델 경량화는 최근 많이 이용되고 있는 pre-trained model의 크기가 점점 커지면서 이를 mobile device나 web 개발에 이용하고자 하여, 활발히 연구되고 있는 분야입니다.
저는 해당 논문을 참고하여 모델 경량화 방법을 설명드릴 것이며, 각 방법 중에서 많이 쓰이고 있는 Weight Sharing, Knowledge Distillation 기법의 예시 논문에 대해서도 설명드리겠습니다.
Source: Xu, Canwen, and Julian McAuley. "A Survey on Model Compression for Natural Language Processing." arXiv preprint arXiv:2202.07105 (2022)
1. Method for Compression of NLP Model

[그림 1] Method for Compression of NLP Model 모델 경량화의 방법으로는 크게 5가지의 기법이 존재한다. 위의 그림에서 Weight Sharing, Low-Rank Factorization, Pruning, Quantization, Knowledge Distillation는 해당 기술의 방법들이다. 크게 5가지의 방법들을 간단히 요약하면 다음과 같다. (그림을 클릭하면, 각 항목마다 간단한 설명을 볼 수 있다.)
- Weight Sharing : 반복되는 구조의 weight matrix를 공유함.
- Low-Rank Factorization : 하나의 weight matrix를 두 개 이상의 작은 행렬로 인수분해하여 저장함.
- Pruning : weight 대응이 불필요한 경우, 연결을 끊어 냄. (ex) 끊어냈을 때, 성능이 떨어지지 않는 것들을 찾음
- Quantization : 모델 weight의 bit 수를 줄임으로써 경량화함.
- Knowledge Distillation : pre-trained model인 Teacher model의 도움을 받아 Student model을 학습함.
2. Weight Sharing
2.1 "Subformer: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers"
weight sharing의 예시 논문으로는 "Subformer: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers" paper가 존재한다.
Source: Reid, Machel, Edison Marrese-Taylor, and Yutaka Matsuo. "Subformer: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers." arXiv preprint arXiv:2101.00234 (2021)
해당 논문은 다음과 같은 두 가지 기법을 사용하여 NLP 모델을 경량화 하였다.
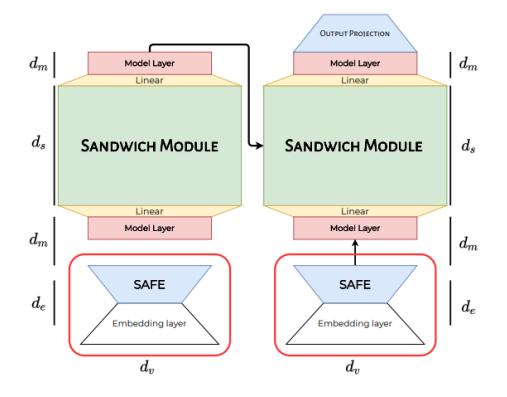
[그림 2] subformer 구조 - SAFE(Self-Attentive Factorized Embeddings)
- Sandwhich Module
먼저, SAFE는 다음과 같은 생각으로 정의되었다.
'transformer 기반 모델들의 Input embedding은 contextualized representation이 아닌 단순 token embedding 이기 때문에, transformer의 hidden state size 보다 더 작게 가져가도 될 것이다.'
Input embedding을 hidden state size보다 작게한 뒤, 다시 원래의 차원으로 돌려주는 연산을 통해 hidden state 차원을 맞추어 주면, weight matrix의 개수는 적으며, 성능이 떨어지지 않는 결과를 가져올 수 있다.
예를 들어, vocab size는 100, embedding size가 10인 transformer weight가 있다고 가정하자.
$V=100, d_{m}=10$ 이 때, embedding matrix의 차원은 $V \times d_{m} =1000$ 이 될 것이다.
하지만, 동일한 vocab size를 취하고 embedding size는 5($d_{v}=5$)로 설정한다면, 이 때, 모델에 들어가기 전 embedding matrix의 차원은 $V \times d_{v} + d_{v} \times d_{m} = 550$으로 절반에 가깝게 weight 크기를 줄일 수 있다.
- SAFE(Self-Attentive Factorized Embeddings)
- Sandwhich Module
Layer sharing은 transformer의 반복되는 layer의 weight을 공유하여 모델을 경량화 하는 기법이다.

[그림 3] Sandwhich module의, # of param, BELU score 이 중에서, 첫 번째와 마지막 Layer를 제외하고 중간의 layer의 weight만 공유한 것이 Sandwhich module이다.
해당 논문의 저자들은 해당 기법이 weight parameter의 수를 크게 줄였고, 성능이 크게 떨어지지 않았다고 주장한다.
2.2 "ALBERT : A Lite BERT for Self-supervised Learning of Language Representations"
weight sharing의 두 번째 예시 논문으로는 "ALBERT : A Lite BERT for Self-supervised Learning of Language Representations" paper가 있다.
Source: Lan, Zhenzhong, et al. "Albert: A lite bert for self-supervised learning of language representations." arXiv preprint arXiv:1909.11942 (2019).
해당 연구에서는 위의 Subformer에서 SAFE layer와 Sandwhich module과 같은 개념의 방법으로 모델을 경량화 하였으며, 기존 BERT와 다른 학습 방법을 통해 성능을 올렸다고 주장한다.
다음과 같이 모델에 쓰인 방법을 소개하면, 아래와 같이 세 가지 방법이 있으며, Factorized Embedding parameter는 Subformer의 SAFE layer와 같이 Embedding layer의 Parameter를 줄이는 방법이고, Cross-layer parameter sharing은 transformer의 같은 구조를 가진 layer에 대해 weight를 공유하는 기법을 말한다.
- Factorized Embedding parameter
- Cross-layer parameter sharing
- Sentence order prediction
이 중에서 Sentence order prediction은 기존 BERT의 학습 방법을 이용하지 않고, 해당 연구에서 사용한 학습 방법이며, 기존 BERT와의 차이점은 다음과 같다.
BERT's Next Sentence Prediction(NSP) training ALBERT's Sentence Order Prediction(SOP) training - 실제 문장과 임의로 뽑은 문장을 이용해 학습함.
- 임의로 뽑은 문장은 앞에 오는 문장과 완전히 다른 Topic 일 확률이 높음.
- 따라서 두 문장 사이의 연관관계를 파악한다기보다, 두 문장이 같은 Topic인지 아닌지를 판단하는 Topic prediction에 가까움.
- SOP 학습 방법은 실제 연속인 두 문장(positive)과 두 문장의 순서를 앞뒤로 바꾼(negative) 문장으로 dataset을 구성함.
- 이는 문장 순서가 옳은지의 여부를 예측하는 방식으로 학습됨.
- 따라서 두 문장 사이의 연관관계를 보다 잘 학습할 것이라고 기대함.
이러한 경량화 기법으로 학습을 진행했을 때, 기존 BERT와의 parameter 개수, 성능을 비교한 표는 다음과 같다.

[그림 4] BERT vs ALBERT, parameter 수 비교 
[그림 5] BERT vs ALBERT, 성능 및 속도 비교
3. Knowledge Distillation
Knowledge Distillation은 최근 많이 연구되고 있는 경량화 기법이다. 이 기법은 pre-trained model(teacher model)과 teacher model보다 구조적으로 사이즈가 작은 student model을 사용한다. teacher model의 feature를 student model에 전달함으로써, 가벼운 모델인 student model의 학습을 도와준다.
대표적으로 DistilBERT(아래 [그림 6]의 (a))는 pre-trained model의 마지막 layer에서 최종 output feature와 student model의 마지막 layer의 output feature 사이의 soft loss를 걸어주며, student model의 최종 output과 Ground Truth(GT)의 Hard loss를 걸어준다.
나머지 (b)-(f)의 모델또한 teacher model의 feature를 student model에 효과적으로 전달해주는 것을 목표로 하며, DistilBERT와의 차이점은 마지막 layer뿐만 아니라, Intermediate layer의 정보들 까지도 student model의 Intermediate layer에 전달하여 teacher model의 knowledge를 더 효과적이고 잘 전달할 수 있도록 한다.

[그림 6] Knowledge Distillation Models 여기까지 NLP 모델의 경량화에 대한 Survey 논문을 review 해보았습니다.
제가 생각했을 때에는 Knowledge Distillation은 학습이 완료된 모델이 필수적으로 요구되기 때문에, 먼저 pre-trained model을 학습해야하고, distillation 과정에서 한 번 더 학습을 해야하는 상황이 번거로운 것 같습니다. 하지만, 애초에 적은 parameter를 사용하여 학습하는 weight sharing은 학습 과정은 한 번 뿐이지만, 성능이 많이 떨어진다는 문제가 있어서 Knowledge Distillation 기법이 많이 연구되고 있는 것 같습니다.
이 다음 장에서는 Knowledge Distillation에서 General Distillation, Task-Specific Distillation의 2-stage 방법을 이용해 모델 경량화를 해도, 성능이 크게 떨어지지 않았다고 소개한 'TinyBERT'를 소개하려고합니다.
'Machine & Deep Learning' 카테고리의 다른 글