-
[yongggg's] QLoRA: Efficient Finetuning of Quantized LLMs ReviewMachine & Deep Learning 2023. 11. 29. 14:06
안녕하세요 이번 장에서는 LoRA finetuning 내용에 이어서 QLoRA라는 paper의 내용을 요약하고자 합니다.
LoRA는 pre-trained LLM의 모든 weights를 fine-tuning하지 않고, pre-trained LLM weights는 모두 freeze 하고 down-stream task를 수행하기 위해 훈련 가능한 rank decomposition matrice를 추가 함으로써 parameter를 효율적으로 훈련하는 방법의 내용을 담고 있었으며, 자세한 리뷰는 저의 다른 페이지에서 확인하실 수 있습니다.
https://yongggg.tistory.com/44
[yongggg's] LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS review
안녕하세요 이번 장에서는 MicroSoft 사의 LoRA 논문을 소개하겠습니다. 2022년 하반기, 2023년 초반기 시점에서 GPT3, GPT4와 같은 LLM이 나와서 큰 이슈가 되고 있습니다. 이 model들은 강력한 성능을 갖고
yongggg.tistory.com
QLoRA는 Low Rank Adapters의 메모리 사용량을 크게 줄이는 효율적인 fine-tuning 접근 방법입니다. 지금부터 이를 요약 해보겠습니다.
Abstract
전체 16-bit의 fine-tuning task 성능을 유지하면서, 단일 48GB GPU에서 65B Parameters 모델을 미세 조정할 수 있을 정도로 메모리 사용량을 줄이는 효율적인 fine-tuning 접근 방법인 QLoRA를 제안한다. QLoRA는 frozen된 4-bit의 양자화 pre-trained model을 통해 gradients를 Low Rank Adapters(LoRA)로 backpropagates한다. 이 방식의 최고 product인 Guanaco는 이전에 공개적으로 출시된 Vicuna benchmark에서 모든 모델의 성능을 능가하며, 단일 GPU의 24시간 미세 조정만 하는 상태에서 ChatGPT 성능 수준의 99.3%에 도달한다.
QLoRA는 성능의 저하를 가져오지 않고 메모리를 절약하기 위해 (a) 4-bit NormalFloat(NF4), (b) quantization constants를 양자화 함으로써 평균 메모리 설치 공간을 줄이는 Double Quantization (c) 메모리 spikes를 관리하는 Paged Optimizer를 소개한다. QLoRA를 1,000개 이상의 model을 fine-tune 하는 데 사용하여 8개의 instruction datasets과 여러개의 model type, 일반 fine-tuning으로 실행할 수 없는 model scales(ex: 33B and 65B parameter model)에 대한 instruction following 및 chatbot 성능에 대한 자세한 분석을 제공한다.
결과적으로 small high-quality datasets에서 QLoRA fine-tuning이 이전 SoTA보다 작은 모델을 사용하는 경우에도 SoTA를 달성하는 결과를 가져온다.
Instruction
Large Language models을 fine-tuning하는 것은 성능을 향상시키기 위해 사용하는 고효율적인 방법이며, 바람직한 동작(output)을 추가하거나 바람직하지 못한 동작을 제거하는 매우 효과적인 방법이다. 그러나 매우 큰 large model을 fine-tuning하는 것은 엄청난 비용이 발생한다. LLaMA 65B parameters model의 regular 16-bit fine-tuing에는 780GB 이상의 GPU 메모리가 필요하다. 반면에, 최근 양자화 방법은 LLM의 footprint를 줄일 수 있지만, 이러한 기술은 Inference 과정에서만 사용되며 훈련 중에는 break down 됩니다.
이 연구에서는 양자화된 4-bit model을 성능 저하 없이 fine-tuning하다는 것이 가능하다는 것을 처음으로 보여준다. QLoRA 방법은 새로운 고정밀 기술을 사용하여 pre-trained model을 4-bit으로 양자화한 다음, 양자화된 가중치를 통해 gradients를 역전파하여 조정된 학습 가능한 Low-rank Adapter weights의 작은 set을 추가한다.
QLoRA는 65B 파라미터 모델을 fine-tuning하는데 필요한 평균 메모리의 요구 사항을 GPU 메모리 780GB에서 48GB로 줄이며, 16-bit의 fully fine-tuned 기준선에 비해 Runtime 혹은 성능의 저하를 가져오지 않는다. 이는 단일 GPU에서 fine-tuning할 수 있는 현재로서 가장큰 모델이다.
QLoRA를 사용하여, Guanaco 모델 군을 훈련했을 때, Vicuna benchmark에서 두 번째 best model은 ChatGPT의 97.8% 성능에 도달 했고, 단일 GPU에서 12시간 내로 훈련할 수 있다. 또, 24시간 동안 단일 GPU를 사용한 가장 큰 모델은 ChatGPT의 99.3%의 성능을 달성했다.
QLoRA는 성능을 저하시키지 않고 메모리 사용량을 줄이기 위해 설계된 여러가지 혁신을 소개한다.
- (1) 4-bit NoramlFloat: 4-bit 정수 및 4-bit float보다 더 나은 실험적 결과를 산출하는 정규분포 데이터의 information theoretically optimal quantization data type이다.
- (2) Double Quantization: 양자화 상수를 양자화 하여 parameter당 평균 약 0.37. bits를 절약하는 방법이다.
- (3) Paged Optimizer: NVIDIA 통합 메모리를 사용하여 sequence 길이가 긴 mini batch를 처리할 때 발생하는 gradient checkpoint의 memory spikes를 방지한다.
이 연구는 이러한 기여 사항을 모든 네트워크 layer에 adapter를 포함하는 더 나은 tuned LoRA 접근 방식에 결합한다. 아래의 Figure 1은 fine-tuning 학습의 다른 점을 나타낸다.
(ChatGPT 성능 비교와 관련된 내용은 Instruction에 기재하여 생략함)
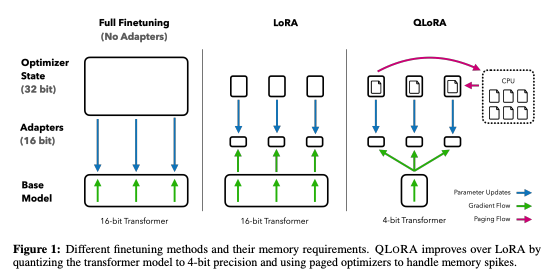
QLoRA Finetuning
QLoRA는 본 연구에서 제안하는 4-bit NF4(Normal Float) 양자화와 이중 양자화의 두 가지 기술을 통해 높은 fidelity의 4-bit fine-tuning을 달성한다. 또한 전통적으로 gradient checkpoint 중 memory spikes로 인해 단일 기계에서 large models이 fine-tuining이 어려웠던 out-of-memory error가 발생하는 것을 방지하기 위해 Paged Optimizer를 도입한다.
QLoRA는 일반적으로 4-bit인 하나의 low-precision storage data 유형과 일반적인 BFloat16인 하나의 computation data 유형이 있다. 실제로 QLoRA 가중치 텐서를 사용할 때마다 텐서를 BFloat16으로 역양자화 한 다음, 16-bit 행렬 곱을 수행한다.
- QLoRA 구성요소
4-bit NormalFlaot Quantization: NF(NormalFloat) 데이터 유형은 각 quantization bin이 입력 tensor에서 동일한 수의 값을 할당받도록 보장하는 information-theoretically optimal한 데이터 유형인 Quantile Quantization을 기반으로 한다. Quantile quantization은 empirical 누적 분포 함수를 통해 입력 텐서의 분위수를 추정함으로써 작동한다.
Quantile quantization의 주요 한계는 분위 추정 과정의 비용이 많이 든다는 것이다. 따라서 SRAM 분위수와 같은 빠른 분위수 근사 알고리즘을 사용하여 이를 추정한다. 이러한 분위수 추정 알고리즘의 대략적인 특성으로 인해 데이터 유형은 종종 가장 중요한 값으로 작용할 수 있는 이상치에 대한 양자화 오류가 크다.
입력 텐서가 양자화 상수까지 고정된 분포에서 나올 때, Expensive quantile estimaes 추정치와 근사 오차를 피할 수 있다. 이러한 경우, 입력 텐서는 동일한 분위수를 가지므로 정확한 분위수 추정을 계산할 수 있다.
pre-trained neural network의 가중치는 일반적으로 표준편차 $\sigma$가 있는 zero-centered normal distribution을 가지므로, 분포가 데이터 유형의 범위에 정확히 맞도록 $\sigma$를 조정하여 모든 가중치를 단일 고정 분포로 변환할 수 있다. 데이터 유형의 경우 임의의 범위 [-1, 1]을 설정한다. 따라서 데이터 유형의 분위수와 신경망 가중치를 모두 이 범위로 정규화 해야한다.
임의의 표준 편차가 [-1, 1] 범위에서 $\sigma$인 zero-mean normal distribution에 대한 optimal data type은 정보 이론적으로 다음과 같이 계산된다. (1) 정규 분포에 대한 k-bit 분위수 양자화 데이터 유형 을 얻기 위해, 이론적 $N(0,1)$ 분포의 $2k+1$분위수를 추정하고, (2) 이 데이터 유형을 사용하여 값을 [-1, 1] 범위로 정규화하고, (3) 입력 가중치 텐서를 absolute maximum rescaling을 통해 [-1, 1] 범위로 정규화하여 양자화 한다.
가중치 범위와 데이터 유형의 범위가 일치하면, normal하게 양자화를 할 수 있다. (3) 단계는 k-bit 데이터 유형의 표준 편차에 맞게 가중치 텐서의 표준 편차를 rescaling하는 것과 같다. 보다 formal하게 데이터 유형의 $2^{k}$값 $q_{i}$를 다음과 같이 추정한다.
$$ q_{i} = {1 \over 2} \bigg( Q \times \bigg( {i \over 2^{k} + 1 } \bigg) + Q \times \bigg( {i + 1 \over 2^{k} + 1} \bigg) \bigg) $$
where $ Q_{x}(\cdot) $ 은 표준 정규분포 $N(0,1)$의 quantile function이다.
symmetric k-bit quantization의 문제점은 이 접근은법이 정확한 0의 표현을 하지 못한다는 것인데, 이는 padding 및 다른 0 값의 value를 오류없이 양자화 하는데 중요한 속성이다. 이산형 0의 zeropoint를 보장하기 위해서, 그리고 k-bit datatype을 위한 모든 $2^{k}$ bits를 사용하기 위해서, 본 연구진은 음수 부분을 위해 $q_{i} : 2^{k-1}$를, 양수 부분을 위해 $2^{k-1}+1$을, 이 두 범위의 분위수 $q_{i}$를 추정하여 비대칭 데이터 유형을 만든 다음, 이러한 $q_{i}$ 집합을 통합하고 두 집합에서 발생하는 두 개의 0중 하나를 제거했다. 데이터 유형은 정보 이론적으로 0-centered normally distributed data에 최적이기 때문에, 각 quantization bin k-bit NormalFloat(NFk)에서, 동일한 기대 값을 갖는 최종 data type을 말한다. 이 data type의 정확한 값은 논문의 부록 E에서 확인 가능하다.
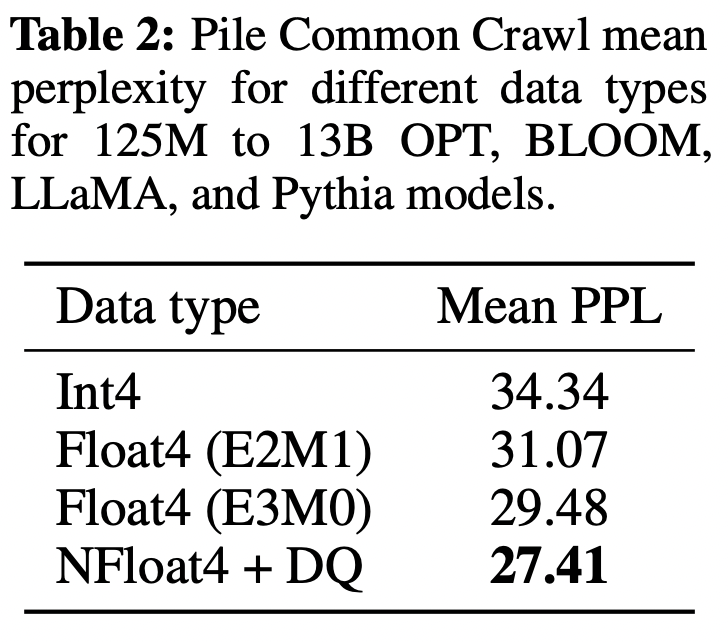
Double Quantization: 추가적인 메모리 절감을 위해 양자화 상수를 양자화 하는 과정이며, 본 논문에서는 "DQ"라고 줄여 소개한다.
정확한 4-bit 양자화를 위해서는 작은 block size가 필요하지만, 메모리 overhead도 상당히 크다. 예를 들어, $W$에 대해 32-bit constants와 64 block size를 사용하면, 양자화 상수는 parameter당 평균 32/64 = 0.5 bit를 추가한다. Double Quantization은 양자화 상수의 메모리 사용량을 줄이는 데 도움이 된다. 보다 구체적으로, Double Quantization은 제 1 양자화의 양자화 상수 $c^{FP32}_{2}$를 제 2 양자화에 대한 입력으로 취급한다. 이 두 번째 단계는 양자화된 양자화 상수 $c^{FP8}_{2}$와 두 번째 level 의 양자화 상수 $c^{FP32}_{1}$을 산출한다. Dettmers와 Zettlemoyer의 결과에 따라 8-bit quantization에 대해 성능 저하가 관찰되지 않으므로 두 번째 양자화에는 block size가 256인 8-bit Float을 사용한다. $c^{FP32}_{2}$가 양수이므로, 양자화 전에, $c2$에서 평균을 빼서 값을 0의 근처로 만든 뒤 대칭 양자화를 사용한다. 평균적으로 block size가 64인 경우 이 양자화는 parameter당 memory footprint를 32/64=0.5 bit에서 8/64 + $32/(64 \cdot 256)$=0.127 bit로 줄여 parameter당 0.373 bits를 줄인다.
Paged Optimizers: GPU가 가끔 out-of-memory를 겪는 상황에서 CPU와 GPU 사이에 오류 없는 GPU 처리를 위해 page-to-oage 자동 전송을 수행하는 NVIDIA 통합 메모리 기능을 사용한다.
이 기능은 CPU RAM과 디스크 사이에서 일반적인 memory paging과 같이 작동한다. 이 기능을 사용하여 optimizer states에 대해 paging된 메모리를 할당한 다음 GPU 메모리가 부족하면 CPU RAM으로 자독 제거되고 optimizer update 단계에서 memory가 필요하다면, 다시 GPU momory로 page 된다.
QLoRA: 위에서 설명한 구성 요소를 사용하여 single LoRA adapter가 있는 quantized based model안의 single linear layer를 다음과 같이 정의한다.
$$ Y^{BF16} = X^{BF16}doubleDequant(c^{FP32}_{1}, c^{k-bit}_{2}, W^{NF4}) + X^{BF16}L^{BF16}_{1}L^{BF16}_{2} \qquad (5)$$
where, $ doubleDequant( \cdot ) $은 다음과 같이 정의한다.
$$ doubleDequant(c^{FP32}_{1}, c^{k-bit}_{2}, W^{k-bit}) = dequant(dequant(c^{FP32}_{1}, c^{k-bit}_{2}), W^{4bit}) = W^{BF16}$$
본 연구에서는 $W$에 대해 NF4를 사용했고 $c_{2}$를 위해 FP8을 사용했다. quantization precision(양자화 정밀도)를 높이기 위해 $W$의 경우 64 block size를 사용했고, 메모리 절약을 위해 $c_{2}$의 경우는 256 block size를 사용했다.
parameter updates의 경우 adapter의 오류에 대한 gradient ${\partial E \over \partial L_{i}}$ 만 필요하고, 4-bit weights에 대한 가중치 ${\partial E \over \partial W}$는 필요하지 않다. 그러나 ${\partial E \over \partial L_{i}}$의 계산은 BFloat16 정밀도에서의 도함수 ${\partial X \over \partial W}$를 계산하기 위해 storage WNF4에서 계산 데이터 유형 WBF16으로 역양자화하여 식 (5)를 통해 진행되는 ${\partial X \over \partial W}$의 계산을 수반한다.
요약하자면, QLoRA에는 하나의 storage data type(보통 4-bit Normal Float)과 computation data type(16-bit BrainFloat)가 있다. storage data type을 computation data type으로 역양자화하여 순방향 및 역방향 패스를 수행하지만 16-bit BrainFloat를 사용하는 LoRA parameter에 대한 weight gradients만 계산한다.
QLoRA vs. Standard Finetuning
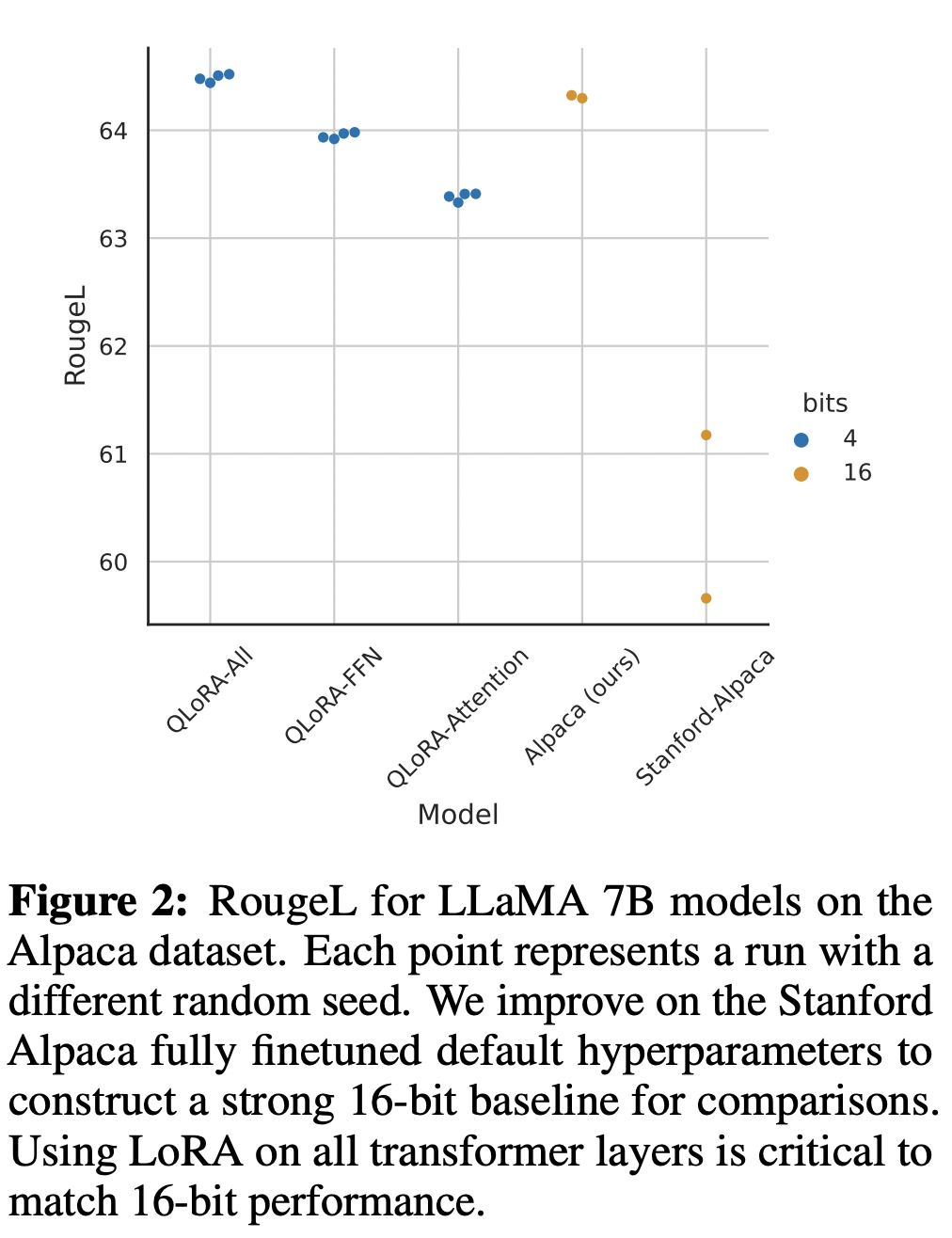
Stanford-Alpaca의 fully finetuned default hyperparameter를 개선 하여 strong 16-bit baseline을 구성했다.
각 점은 다른 random seed를 가진 runs을 나타낸다.
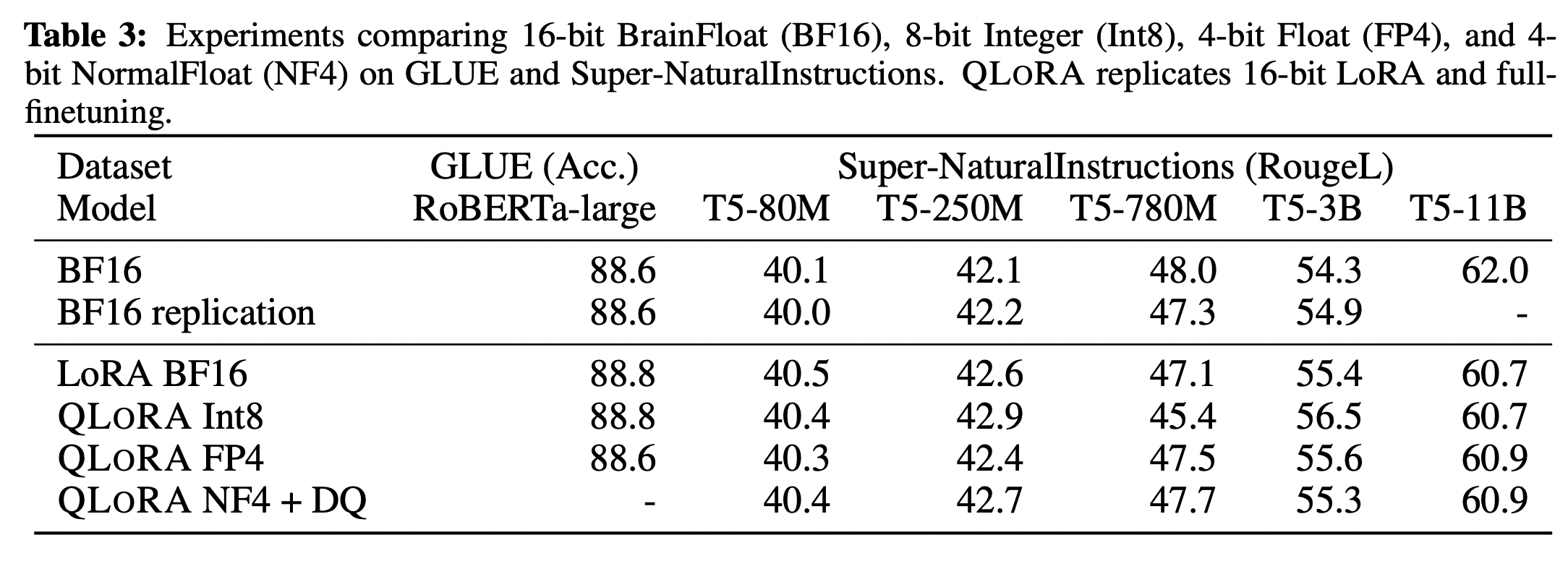
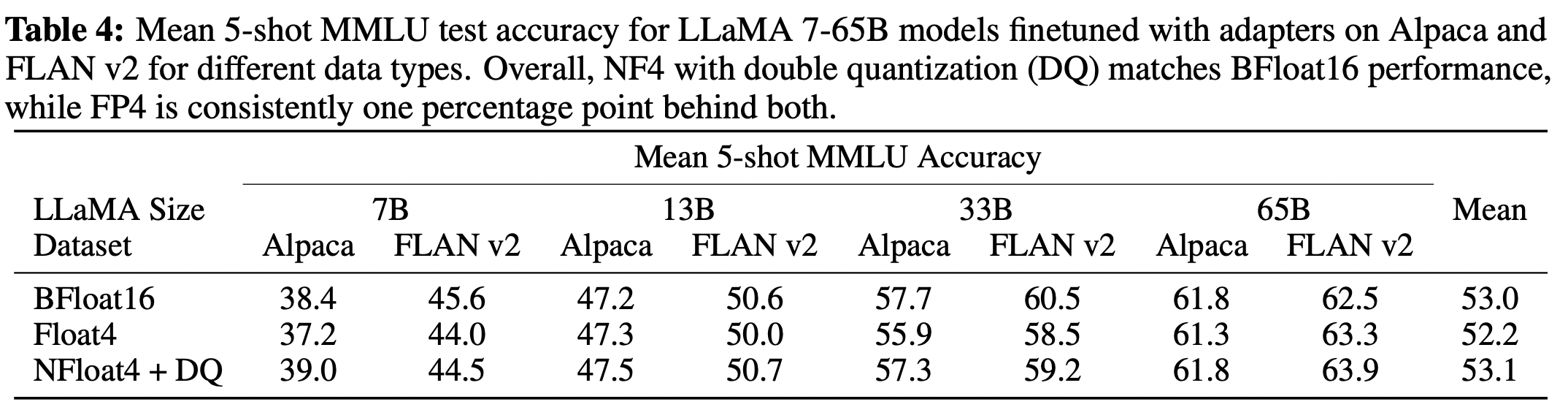
NormalFloat data type은 일반 4-bit Float에 비해 bit당 정확도를 크게 향상 시킨다. DQ(Double Quantization)는 약간의 minor gains만 가져오지만, memory footprint를 보다 세밀하게 제어하여 특정 크기(33B/65B) 모델을 특정 GPU(24/48GB)에 맞출 수 있다. 또한 16-bit를 4-bit로 줄여도 그 성능이 떨어지지 않았다.
같은 bit를 사용한다고 했을 때, QLoRA를 사용한다면, 그 성능이 더 좋다.
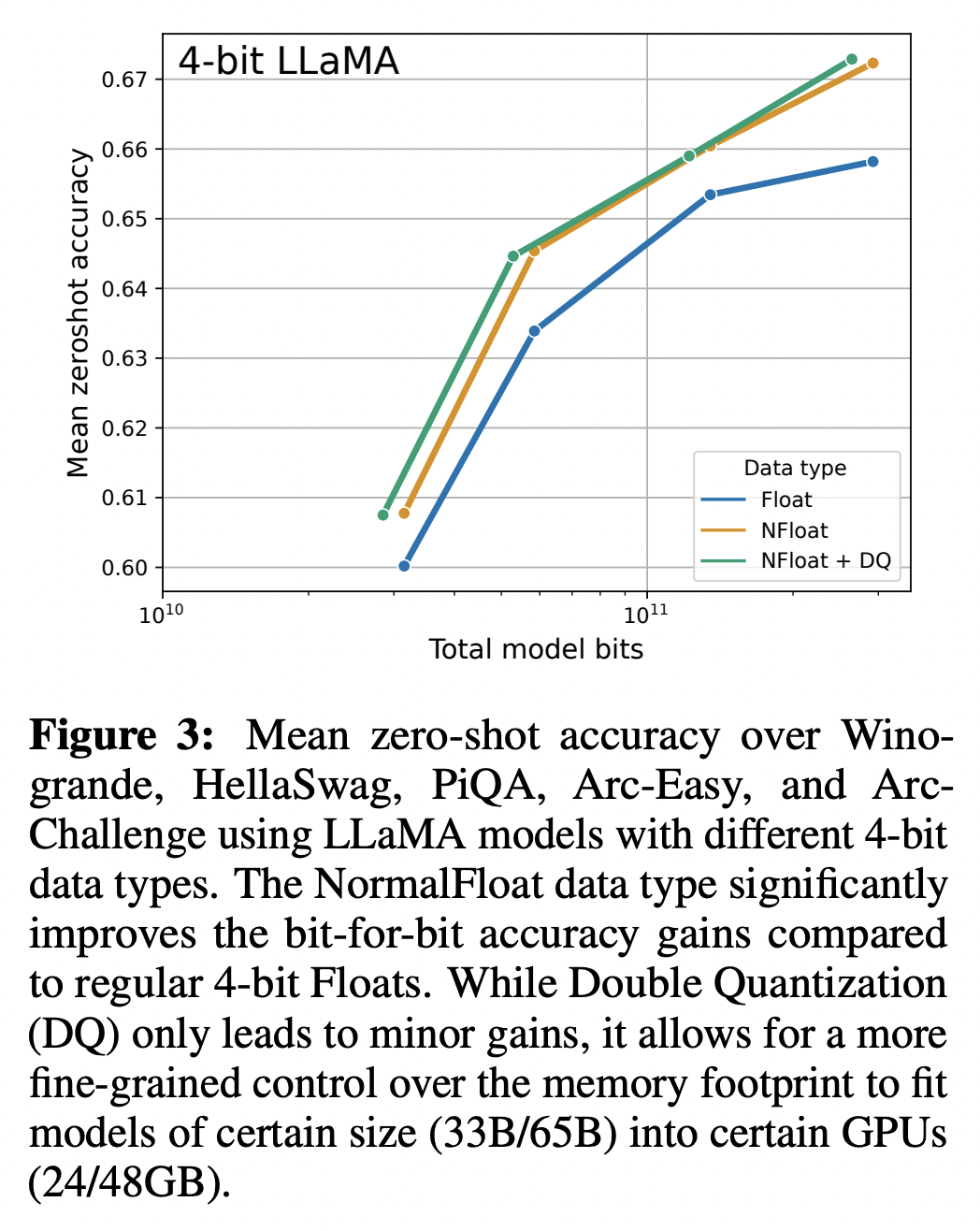
다음의 실험들에서는 각각의 metric에 대해 QLoRA에서 사용한 data type 및 기법들의 우수함을 나타낸다.
'Machine & Deep Learning' 카테고리의 다른 글