-
[yongggg's] Optimizer & Learning Rate SchedulerMachine & Deep Learning 2023. 1. 17. 16:24
안녕하세요 이번 글에서는 Learning rate scheduler(lr scheduler)에 관련한 내용을 다뤄보고자 합니다. 대학생 때부터 대학원생까지 이 개념을 계속 봐와서 너무 당연하게 여겨, 다시 한 번 정리하는 차원에서 글을 작성합니다 ^^...
예전에 optimizer와 lr scheduler를 학습 과정에서 단순히 복붙하며 중요성을 모른채 사용했었지만, 이번 프로젝트에서 checkpoint 저장 및 이어서 학습하는 코드를 직접 구현하면서, 이 것들의 중요성 또한 깨달아서 반성하며 글을 작성했습니다.
이제 설명 하겠습니다!
Optimizer
최적화(optimize)란 딥러닝 모델이 예측한 결과물을 정답과 비교하여 나온 수치 즉, Loss 함수의 수치를 최대 혹은 최소로 만들 때 어떤 방식으로 이 수치를 최대 혹은 최소로 만들 지에 대한 방법을 말한다.
결과적으로 딥러닝에서 모델을 학습시킨다는 것은, 최적화 문제를 해결하는 것과 같습니다.
Optimizer의 Algorithm은 현재 다양하게 연구가되어 나와있지만, 다음 블로그를 참고하면 좋을 것 같다.
5) 옵티마이저
일반적으로는 Optimizer라고 합니다. 뉴럴넷의 가중치를 업데이트하는 알고리즘이라고 생각하시면 이해가 간편하실 것 같습니다. 가중치를 업데이트하는 방법은 경사하강법에서 …
wikidocs.net
pytorch framework를 기준으로 다음과 같이 사용할 수 있다.
# define optimizer optim = optim.SGD(model.parameters(), lr=0.1, momentum=0.9) # or optim = optim.Adam([va1, var2], lr=0.001)위의 코드와 같이 자신이 사용하고자 하는 optimizer를 정의한 뒤에, iteration 과정에서 다음과 같이 최적화를 수행할 수 있다.
for i, data in enumerate(data_iter): optim.zero_grad() output = model(data['input']) loss = loss_fn(output, data['target']) loss.backward() optimizer.step()여기서 optimizer의 gradient를 각 iter마다 0으로 초기화 해주기 위하여, optim.zero_grad()를 사용한다.
pytorch optimizer는 미분을 통해 얻은 기울기를 이전에 계산된 기울기 값에 누적시키도록 짜여있기 때문에, optim.zero_grad()를 해주어야 한다.
Learning Rate Scheduler
하지만, 이 optimizer 만을 사용한다면, 어떻게 될까?
가령 다음과 같은 목적함수를 갖는 데이터가 있다고 하자.
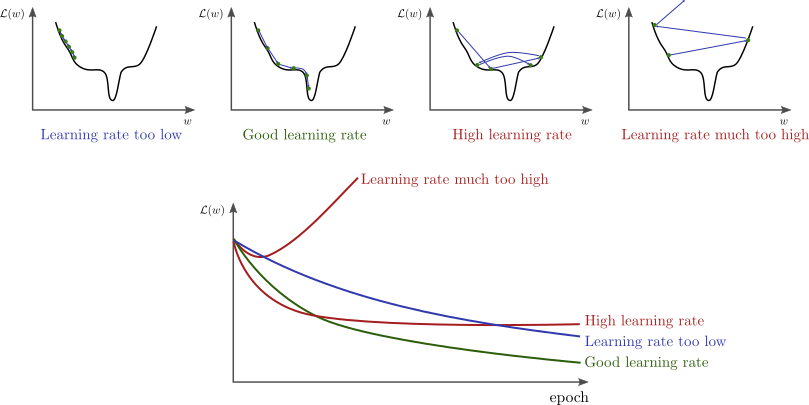
source : http://www.bdhammel.com/learning-rates/ optimizer의 learning rate가 각기 다른 상황을 살펴보면, 너무 작은 learing rate를 가지고 최적화를 진행한다면, 함수의 최소/최대에 다가가기에 너무 느리다. 더 큰 문제로는 저 최소점이 local 최적해일 수도 있다는 것이다. 또한, 너무 큰 learning rate를 가지고 최적화를 진행한다면, 네 번째 그림과 같이 loss가 발산하는 모습을 볼 수 있다.
이렇게 local 최적해에 갇히는 문제, 혹은 loss가 발산하는 문제를 해결하기 위해 learning rate scheduler를 사용한다.
제일 간단한 scheduler를 생각해보자면, 적당히 큰 learning rate 값으로 시작하여, 이 learning rate를 점점 줄여가는 것이다.
이렇게 학습을 진행 했을 때, 시작 point의 loss 값에서 local 최적해에 갇힐 확률도 현저히 줄어들 뿐만 아니라, 너무 큰 learning rate 때문에 loss가 발산할 확률 또한 현저하게 줄어든다.
위처럼 가장 간단한 방법 이외에 learning rate scheduler는 많은 연구가 이루어졌다. 여기서 신기한 연구 중에 하나는 learning rate를 줄였다 늘렸다 하는 것이 더 성능향상에 도움이 된다는 연구결과도 존재했다.
이 scheduler 또한 pytorch framework를 기준으로 다음과 같이 쉽게 사용할 수 있다.
# define scheduler ## normally last_epoch = -1 scheduler = optim.lr_scheduler.LambdaLR(optim, lambda, epoch, last_epoch, verbose=False)위의 코드와 같이 자신이 사용할 scheduler를 정의한 뒤, 학습 코드에서 다음과 같이 코드를 작성하면 된다. (이 때, scheduler를 epoch 기준으로 작동할 것인지, iteration 기준으로 작동할 것인지는 본인의 선택이다. 아래 코드는 iteration을 기준으로 scheduler를 작동 시키고 싶을 때의 예시이다.)
for epoch in range(EPOCHS): for i, data in enumerate(data_iter): optim.zero_grad() output = model(data['input']) loss = loss_fn(output, data['target'] loss.backward() optim.step() scheduler.step()오늘은 위의 내용과 같이 optimizer와 scheduler를 사용하는 방법에 대해 설명드렸습니다. 대학교 수업이나 대학교 강의에서 많이 배우셨을 텐데, 직접 custom 하거나 사용자 마음대로 사용하실 경우가 있을 때 이 글을 읽으시고 도움이 됐으면 좋겠습니다.
긴글 읽어 주셔서 감사합니다! 질문이나 오타, 잘못된 내용은 댓글로 남겨주세요 ^^
'Machine & Deep Learning' 카테고리의 다른 글