-
[yongggg's] Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (Fusion in Decoder) 논문 리뷰Machine & Deep Learning 2022. 12. 13. 15:56
안녕하세요 이번 장에서는 이전의 DPR에 이어 retrieved passages 에서 질문에 맞는 답을 생성할 수 있도록 해주는 모델에 대해 설명드리고자 합니다.
이전 연구에서는 이를 passages들에서 spans을 찾아 가져오는 것으로 해결하였는데, 이 연구에서는 직접 생성을 통해 답을 만드는 것이 성능이 더 높았다는 것을 담은 연구입니다.
이를 구현할 때, 같은 batch에 하나의 Set이 들어간다는 것이 정말 참신한 연구였던 것 같습니다.
(한 배치안에는 하나의 세트 즉, 질문과 하나의 positive passages representations을 Concat한 것, 질문과 여러개의 negative passages representations을 Concat한 것이 구성되어 있습니다.)
본 연구의 요약은 모두 번역하지 않았으며, 읽으면서 중요한 내용들을 담아보았습니다. 다른 자세한 내용도 꼭 논문을 찾아서 읽어보시는 것을 추천합니다!
Abstract
Open Domain Question Answering을 위한 생성모델은 외부 지식에 의존하지 않고 경쟁력이 있는 것으로 입증되었다. 이 접근 방식은 유망하지만 수십억 개의 매개 변수를 가진 모델을 사용해야 하며, 이는 훈련 및 query에 비용이 많이 든다. 본 연구에서는 이 모델이 잠재적으로 evidence를 포함하는 retrieving text passages에서 얼마나 많은 이익을 얻을 수 있는지 조사한다.
NQ와 TriviaQA benchmark datasets 에서 SoTA를 달성했으며, 흥미롭게도 검색된 구절의 수를 증가시킬 때, 이 방법의 성능이 크게 향상된다는 것을 관찰했다. 이 점은 S2S 모델이 여러 구절에서 증거를 효율적으로 집계하고 결합할 수 있는 유연한 framework를 제공한다는 증거이다.
1 Introduction
Document 로부터 답을 추출하기 이전에, support documents를 검색함으로써 먼저 이 시스템이 작동한다. 이 때, 다른 TF/IDF의 sparse representations 혹은 dense embedding과 retrieval techniques을 이용해 documents를 검색할 수 있다. 이 documents와 text의 representation을 갖고 문맥화된 word representations로 부터 답을 뽑아내는 모델 (ex. ELMo or BERT) 등은 answer의 span을 예측한다.
Multiple passages에서 증거를 집계하고 결합하는 것은 추출 모델을 사용할 때 간단하지 않으며, 이러한 한계를 해결하기 위해 여러 기술이 제안되었다. (Clark and Gardner, 2018; Min et al., 2019a). 본 논문에서는 개방형 도메인 질문 답변을 위한 생성 모델링 및 검색의 흥미로운 발전을 기반으로 두 tasks 세계의 장점을 모두 갖춘 간단한 접근 방법을 탐구한다. 이 방법은 두 단계로 진행되는데, 첫 번째로 sparse or dense representation을 사용하여 supporting passages를 검색한다. 그 다음, s2s 모델은 질문 외에 다시 검색된 구절을 입력으로 사용하여, 답변을 생성한다.
이 방법은 간단하지만, TriviaQA와 Natural Question에서 SoTA를 달성하였다. 특히, 본 연구에서는검색된 passages의 수가 증가할 때 본 연구의 방법의 성능이 크게 향상된다는 것을 보여준다. 이 점은 생성 모델이 추출 모델에 비해 여러 구절의 증거를 결합하는데 능숙하다는 증거이다.
2 Related Work
OpenQA : 대규모 문서들이 있는 곳에서 질문을 던졌을 때, 답을 다음과 같은 과정으로 찾는 task이다. passage를 찾는 context retrieval 과정이후, retrieve 된 문단에서 실제 답변을 찾는 reading 과정의 2 step으로 이루어진 task이다.
Passage retrieval : sparse 혹은 dense의 document representations을 통해 질문에 알맞는 passages를 검색하는 task이다.
Generative question answering : OpenQA의 두 번째 단계에서 실제 답변을 찾는(span을 찾는) 방법이 아닌 직접 생성을 하는 task이다. Min et al. (2020) and Lewis et al. (2020)의 generative model과 다르게, 본 연구의 접근 방식은 generative model이 retrieved passages를 처리하는 방법에 차이가 있다. 본 연구의 방식을 통해 많은 수의 문서로 확장할 수 있으며, 많은 양의 evidence를 활용할 수 있다.
3 Method
이번 장에서는 본 연구의 open domain question answering에 대한 접근 방법을 소개한다. Supporting passages를 검색하는 단계와 S2S 모델로 supporting passages를 처리하는 단계의 두 단계로 진행된다. 아키텍처는 다음 그림과 같다.

Retrieval.
Support passages를 검색하기 위해 본 연구에서는 BM25 방법과 DPR 방법을 선택했다.
Reading
본 연구의 Open QA를 위한 Generative model은 S2S network를 기반으로 하며, unsupervised data에 pretrained되어 있는 T5와 BART 같은 모델로 구성된다. 이 모델은 질문과 support passages를 입력으로 받아들여 답을 생성한다. 더 정확하게는, 각각의 retrieved passages와 그 제목은 질문과 연결되며, Encoder에 의해 다른 passages로부터 독립적으로 처리된다. 본 연구에서는 special tokens으로 “question:”, “title:”, “context:”를 각 passages의 question, title, context 앞에 추가하였다. 마지막으로 decoder는 모든 retrieved passages의 representations 결과를 concat한 뒤에 attention을 수행한다. 본 연구에서 이 모델을 Fusion-in-Decoder라고 언급한다. Encoder에서는 passages를 독립적으로 처리하지만, decoder에서는 이를 joint하여 처리함으로써, 이 방법은 Min et al. (2020) and Lewis et al. (2020).의 방법과 다르다. Encoder에서 독립적으로 passages를 처리하면, 한 번에 하나의 context에서만 self-attention을 수행하기 때문에, 많은 context로 확장할 수 있다. 이것은 passages의 수에 따른 모델의 계산 시간이 quadratic 하게 증가하는 것이 아닌, linear하게 증가한다는 것을 의미한다. 반면 Decoder에서 joint하게 passages를 처리하면, multiple passages에서 evidence를 더욱 잘 집계할 수 있다.
4 Experiment
Dataset:
NaturalQuestions
TriviaQA
SQuAD v1.1
Evaluation
예측된 답변은 Rajpurkar et al.(2016)이 도입한 표준 정확 일치 메트릭(EM)으로 평가한다. 정규화 후에 허용 가능한 답변 목록의 답변과 일치하는 경우 생성된 답변이 올바른 것으로 간주된다. 이 정규화 단계는 articles, 구두점 및 중복된 공백을 제거하고, 소문자로 바꾸는 단계로 구성한다.
Technical details
본연구에서는 pretrained T5 models로 실험했다. 모델의 크기는 base와 large 이며, 각각 220M, 770M 개의 parameters를 가진다. 또한 이 모델을 base로 각 데이터셋에 fine-tuning 했다.
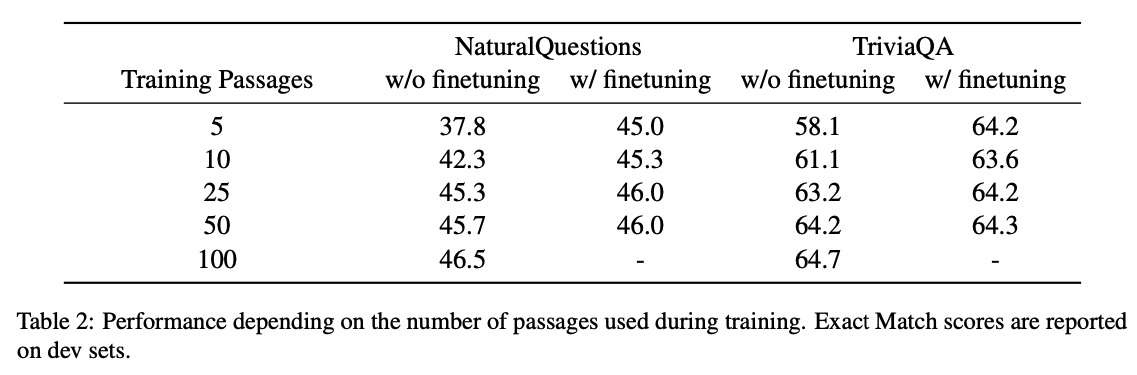
Comparisons to SoTA
기존 SoTA를 능가한다는 것을 알 수 있으며, 다른 생성 모델보다 성능이 우수하다. 특히 생성 모델은 Extraction approach에 비해, 여러 구절의 evidence를 집계할 때, 성능이 높은 것으로 보인다. 본 연구의 모델은 많은 수의 passsages로 확장하고, 이를 공동으로 처리하면 정확도가 높아진다는 것을 보여준다. 또한 검색을 사용하여 생성 모델에서 추가 지식을 사용하면 성능 향상이 된다는 것을 확인했다.
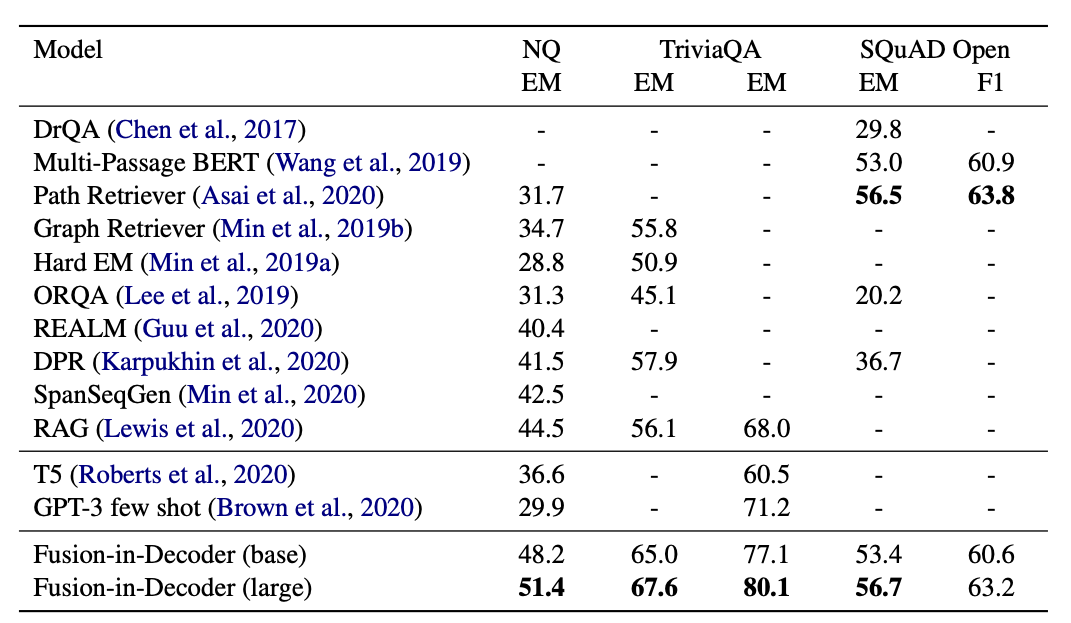
Scaling with number of passages & Impact of the number of training passages
Retrieved passages의 수가 증가할 수록 성능이 높아지며, 학습과 평가에서는 같은 수의 retrieved passages를 사용했다.

4 Conclusion
본 논문을 참고.
위의 방법은 검색하는 데 많은 수의 passages를 상대로 속도 개선이 되었다는 점도 유의 깊게 봐주셨으면 좋겠습니다!
긴 글을 읽어주셔서 감사합니다. 잘못된 내용이나 오타 등 궁금하신 것들은 댓글 남겨주시면 감사하겠습니다!!! ^^
'Machine & Deep Learning' 카테고리의 다른 글