-
[yongggg's] Graph Convolutional Networks for Text ClassificationMachine & Deep Learning 2022. 8. 8. 14:22
안녕하세요 yonggg's 블로그 입니다.
이번 시간에는 Graph Embeddings에 대해 공부하는 시간을 갖도록 하겠습니다.
이를 설명하기 위해, "Graph Convolutional Networks for Text Classification"이라는 논문을 선정했습니다."Yao, Liang, Chengsheng Mao, and Yuan Luo. "Graph convolutional networks for text classification." Proceedings of the AAAI conference on artificial intelligence. Vol. 33. No. 01. 2019."
이 논문을 선정한 이유는 Graph 이론을 이용해 Text Task에 적용된 논문들 중에, Text Embeddings 및 Document Embedding 그리고 Classification을 모두 End-to-End로 학습하는 딥러닝 모델이며, 가장 기초적이고 이해하기 쉬운 논문이기 때문입니다.
그렇다면, 설명을 시작하겠습니다.
Word Embeddings
먼저, Word Embeddings이 무엇인지 부터 알아보자.
오래 전 NLP 연구진들은 단어를 one-hot vector로 표현하여 사용했다. 하지만 이 방법은 단어 간의 연관성이 없다는 것을 반영하지 못한다. 따라서 연구진들은 word representation을 각 단어의 연관성을 반영하고 싶었다. 다시 말해, [그림 1] 처럼 비슷한 단어는 비슷한 space에 위치 시킨다던지, King과 man에 방향과 크기가 같은 벡터를 더했을 때, Queen과 Women이 나오도록 관련성을 반영하여 word를 vector로 표현하고자 했다. 이런 word vector 자체가 잠재적인 의미를 내포하도록 단어를 공간상으로 mapping 해주는 것이 word embedding이라고 할 수 있다.

[그림 1] word embeddings Graph Theory & Graph Convolution (Neural) Network
이 설명은 하나의 소주제로 https://yongggg.tistory.com/29 해당 글에서 설명했습니다.
오늘 논문을 이해하시는데 GCN 개념을 모르시는 분들은 위의 링크에서 설명을 보고 오시는 것을 추천합니다.
Word Embedding vs Word Graph Embedding
그렇다면, 오늘 알아볼 Word Grpah Embedding은 무엇일까?
위의 Word Embedding을 Graph를 활용하여 학습 시키는 것이라고 이해할 수 있다. word embedding을 어떻게 학습하는지 부터 알아보기 위해 word embedding의 대표적인 방법으로 Word2Vec의 skip-gram을 보자.
(중심 단어의 전과 후에 발생한 단어를 입력으로 중간 단어를 예측하는 CBOW 보다 학습 loss가 많은 skip-gram의 성능이 대체로 좋으며, 이와 관련된 자세한 내용은 생략한다.)

[그림 2] Word2Vec Skip-Gram [그림 2]처럼 skip-gram은 다음과 같은 방식으로 word embedding을 학습한다.
- 먼저, 문장에서 몇 개의 단어(sliding window size)를 볼건지를 정한다. (홀수개로 지정함)
- sliding window 안의 중간 단어를 기준으로 모델의 input으로 넣는다.
- 기준이 된 중간 단어의 전과 후에 발생한 단어들을 예측한다.
- 실제 단어들과 예측 단어의 loss를 통해 기준이 된 중간 단어의 벡터를 update 한다.
이렇게 Vocab에 구성한 모든 단어에 대해 업데이트를 마치면, 하나의 word embedding matrix가 학습되는 것이다.
위와 같이 Word Graph Embedding도 마찬가지로 word(or documnet) node로 구성된 Graph가 building된 후, 학습 과정에서 업데이트 할 node에 연결된 node에만 loss가 걸리며, backword loss 연산 과정으로 해당 노드가 update 된다. 이 때, node에 들어있는 feature vector가 node의 representation이 되는 것이다. (node가 word로 구성되어 있다면, text embedding document로 구성되어 있다면, document embedding 표현이 되는 것이다.)
Graph convolutional networks for text classification
이제 소개에서 언급했던 Graph convolutional networks for text classification을 이해할 준비가 모두 끝났다.
본 연구에서는 text 및 document 정보를 그래프로 building 하였으며, 궁극적으로 text classification 문제를 풀었다. 이때 text classification을 진행하는 과정에서 text embedding과 document embedding이 함께 학습됐다고 한다.
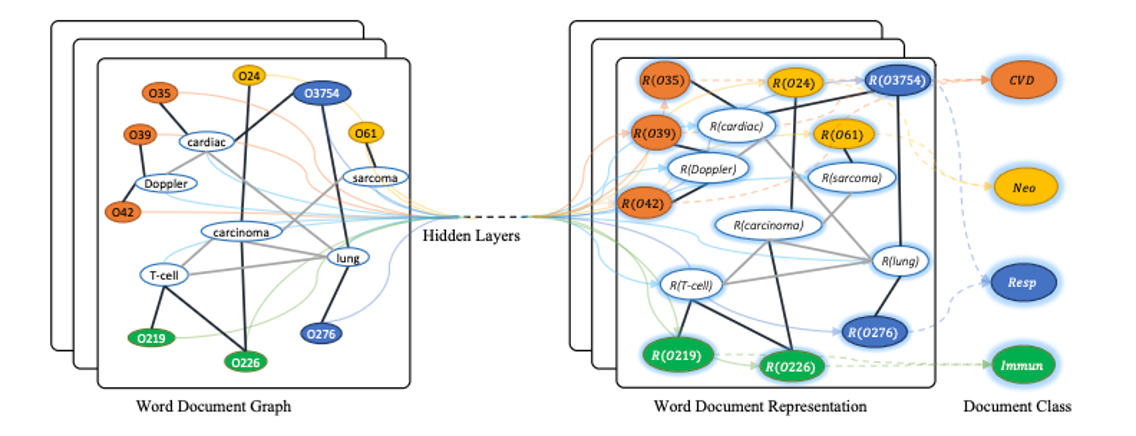
[그림 3] Schematic of Text GCN 본 연구에서는 Vertex를 word node와 document node로 구성했다. [그림 3]에서 흰색 풍선은 word를 나타내고 색이 있는 풍선은 document code를 나타낸다. (각 단어와 관련된 document들과 각 단어를 이용하여 document의 class를 예측하는 것이다.)
[그림 3]의 오른쪽의 $R$( $\bullet$ )함수는 word와 document를 지정 차원으로 매핑하는 representation 함수를 나타내며, 이 값은embedding matrix와 같다.
구성한 노드를 바탕으로 Edge 정보를 구축해야 Graph가 완성이 되는데, Edge는 어떻게 구성했을까?
본 연구에서는 word-document 사이의 Edge와 word-word 사이의 Edge를 다른 방법으로 구성했으며, 구성 방법은 다음과 같다.
- word-document Edge : TF-IDF score를 사용함
- word-word Edge : corpus의 모든 docuemnt에 대해 고정 크기의 sliding window를 사용하여 그 안에서 두 단어가 동시에 나올 동시 발생 확률을 사용하는 Point-wise Mutual Information(PMI)를 사용함
그럼 TF-IDF와 PMI가 무엇인지 자세하게 알아보자.
TF-IDF
TF-IDF는 Corpus에서 특정 word가 얼마나 중요한지를 나타내는 측도이다. TF와 IDF는 다음 설명과 같다.
- TF(Term Frequency) : 특정 문서에서 특정 단어가 몇 번 나타냈는지를 나타냄; ($tf_{1,doc1}$)
- IDF : DF 값의 역수의 로그 값; ($log_{10}({N \over df_{t}})$ where N is # of corpus)
- DF : 전체 문서 D에서 특정 단어가 등장한 문서 개수; ($df_{t}$)
이를 예시를 통해 자세히 살펴 보자.
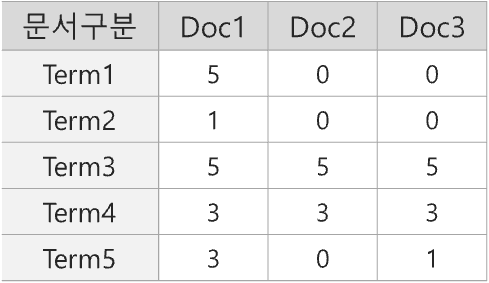

Corpus의 문서는 3개로 각각 Doc1 ~ Doc3 까지 존재하며, Corpus에 등장하는 단어를 Term1 ~ Term5라고 가정하자.
이 때, Doc1 을 기준으로 TF는 Doc1에 나온 Term1 ~ Term5 의 빈도 수와 같다.
Doc1을 기준으로 Term1에 대한 DF는 해당 단어가 Doc2, Doc3에서는 등장하지 않고 Doc1에서만 등장했기 때문에 1로 count 되는 것을 볼 수 있다. 반면 Term4 는 전체 문서에 모두 등장했기 때문에 Corpus안의 document 수인 3으로 count 되었다.
이제 Doc1을 기준으로 $log_{10}({N \over df_{t}})$ 연산을 해주면 IDF 값이 나오는 것을 알 수 있으며, TF-IDF score는 TF 값과 IDF 값을 곱한 값이며, 다음과 같이 나타낼 수 있다.
$$ TF-IDF(w) = tf(w) \times log({N \over df(w)}) $$
이 논문은 이 score를 word-document edge weight로 사용하였다.
Point-wise Mutual Information(PMI)
다음은 본 논문에서 word-word 간의 Edge를 구성할 때, 사용한 방법이다.
이 것을 구하는 식은 다음과 같다.
- $p(i) = {N_{W}(i) \over N_{W}} $
- $p(i,j) = {N_{W}(i,j) \over N_{W}} $
- $PMI(i,j) = log{p(i,j) \over p(i),p(j)} $
where, $N_{W}$: Corpus 안의 sliding windows의 총 개수, $N_{W}(i)$: word i를 포함하는 corpus 안의 sliding windows의 수,
$N_{W}(i,j)$: word i와 word j를 모두 포함하는 sliding windows의 수
구하는 방법을 단계별로 설명하면 다음과 같다.
- document를 훑을 고정 크기의 windows size를 정한다.
- document를 몇개 훑을 수 있을지 그 숫자를 센다. -> 위의 $N_{W}$
- 이 훑는 과정에서 특정 word i가 나오는 sliding window 개수를 센다. -> 위의 $N_{W}(i)$
- 이 훌튼 과정에서 특정 word i 와 word j가 동시에 나오는 sliding window 개수를 센다. -> 위의 $N_{W}(i,j)$
- PMI 공식을 통해 PMI를 구한다.
이 값이 양수라면, 의미적 관계가 있다는 뜻이며, 이 값이 음수라면, 거의 없거나 아예 없는 의미적 관계라고 칭할 수 있습니다. 따라서 양수인 PMI에만 weighted edges를 추가합니다. 이렇게 word-word 간의 Edge도 추가하였다.
이렇게 Vertex와 Edge를 구하여 graph building을 했다. 본 연구는 이 데이터를 이용하여 GCN 과정을 통해 text classification 및 text와 document embedding을 진행했다.
GCNs
본 연구에서는 2 개의 GCN Layers를 사용했다. 이는 2단계 떨어진 node의 feature 정보까지 반영한다는 말이다.
$$ Z = softmax(\tilde{A} ReLU(\tilde{A} X W_{0}) W_{1}) \\ where \tilde{A} = D^{-1/2}AD^{-1/2}, softmax(x_{i})= {1 \over z} exp(x_{i}) \; with \; Z = \sum_{i} exp(x_{i}) $$
첫 번째 Layer를 통과한 output에 비선형 함수인 ReLU를 적용했으며, 두 번째 Layer를 통과한 output에는 softmax함수를 걸어 분류 score를 출력하였다.
Loss 는 모든 labeld document에 대해 cross-entropy error를 사용한다.
$$ L = - \sum_{d \in \mathcal{Y}_{D}} \sum_{f=1}^{F} Y_{df} lnZ_{df} \\ where \; \mathcal{Y}_{D} : labeld \; document's \; indices, \; Y : \; label \; indicator \; matrix$$
Results
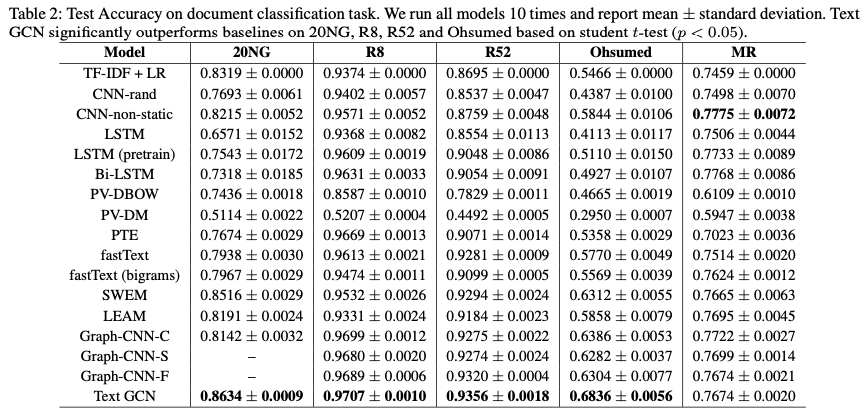
[그림 4] Results of GCNs model 본 논문에서 나온 결과는 다음과 같다. 대부분의 embedding 기반 classifier보다 우수한 성능을 가졌으며, LSTM 등의 sequnce model 혹은 CNN 모델보다 우수한 성능을 가졌다.
이렇게 GCNs for text classification 논문 리뷰를 마치겠습니다. 긴 글이었지만 읽어주셔서 감사합니다. 내용의 오류나 궁금한 사항 등을 댓글로 남겨주시면 정말 감사하겠습니다 !! ^-^
'Machine & Deep Learning' 카테고리의 다른 글